Compare commits
4 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 89ec179890 | |||
| bc15d65033 | |||
| 76c6327d88 | |||
| 8f53280478 |
293
Pixiv.py
293
Pixiv.py
@ -1,293 +0,0 @@
|
||||
"""
|
||||
P站小爬虫 爬每日排行榜
|
||||
环境需求:Python3.8+ / Redis
|
||||
项目地址:https://github.com/nyaasuki/PixivSpider
|
||||
|
||||
"""
|
||||
|
||||
import re
|
||||
import os
|
||||
|
||||
try:
|
||||
import requests
|
||||
import redis
|
||||
|
||||
except:
|
||||
print('检测到缺少必要包!正在尝试安装!.....')
|
||||
os.system(r'pip install -r requirements.txt')
|
||||
import requests
|
||||
import redis
|
||||
|
||||
requests.packages.urllib3.disable_warnings()
|
||||
error_list = []
|
||||
|
||||
|
||||
class PixivSpider(object):
|
||||
|
||||
def __init__(self, db=0):
|
||||
self.ajax_url = 'https://www.pixiv.net/ajax/illust/{}/pages' # id
|
||||
self.top_url = 'https://www.pixiv.net/ranking.php'
|
||||
self.r = redis.Redis(host='localhost', port=6379, db=db, decode_responses=True)
|
||||
|
||||
def get_list(self, pid):
|
||||
"""
|
||||
获取作品所有页面的URL
|
||||
:param pid: 作品ID
|
||||
"""
|
||||
try:
|
||||
# 检查Redis中是否已记录该作品已完全下载
|
||||
if self.r.get(f'downloaded:{pid}') == 'complete':
|
||||
print(f'作品ID:{pid}已在Redis中标记为完全下载,跳过')
|
||||
return None
|
||||
|
||||
# 发送请求获取作品的所有图片信息
|
||||
response = requests.get(self.ajax_url.format(pid), headers=self.headers, verify=False)
|
||||
json_data = response.json()
|
||||
|
||||
# 检查API返回是否有错误
|
||||
if json_data.get('error'):
|
||||
print(f'获取作品ID:{pid}失败:{json_data.get("message")}')
|
||||
return pid
|
||||
|
||||
# 从返回数据中获取图片列表
|
||||
images = json_data.get('body', [])
|
||||
if not images:
|
||||
print(f'作品ID:{pid}没有图片')
|
||||
return pid
|
||||
|
||||
# 获取Redis中已下载的页面记录
|
||||
downloaded_redis = set()
|
||||
for i in range(len(images)):
|
||||
if self.r.get(f'downloaded:{pid}_p{i}') == 'true':
|
||||
downloaded_redis.add(i)
|
||||
|
||||
# 检查本地已下载的文件并更新Redis记录
|
||||
if os.path.exists('./img'):
|
||||
for f in os.listdir('./img'):
|
||||
if f.startswith(f'{pid}_p'):
|
||||
page = int(re.search(r'_p(\d+)\.', f).group(1))
|
||||
if self.r.get(f'downloaded:{pid}_p{page}') != 'true':
|
||||
self.r.set(f'downloaded:{pid}_p{page}', 'true')
|
||||
print(f'发现本地文件并更新Redis记录:{f}')
|
||||
|
||||
# 使用Redis记录作为唯一来源
|
||||
downloaded = downloaded_redis
|
||||
|
||||
# 遍历所有图片进行下载
|
||||
for image in images:
|
||||
# 检查图片数据格式是否正确
|
||||
if 'urls' not in image or 'original' not in image['urls']:
|
||||
print(f'作品ID:{pid}的图片数据格式错误')
|
||||
continue
|
||||
|
||||
# 获取原图URL和页码信息
|
||||
original_url = image['urls']['original']
|
||||
page_num = int(re.search(r'_p(\d+)\.', original_url).group(1))
|
||||
|
||||
# 检查是否已下载过该页面(优先使用Redis记录)
|
||||
if page_num in downloaded:
|
||||
print(f'作品ID:{pid} 第{page_num}页在Redis中已标记为下载,跳过')
|
||||
continue
|
||||
|
||||
# 下载图片,如果下载失败返回作品ID以便后续处理
|
||||
why_not_do = self.get_img(original_url)
|
||||
if why_not_do == 1:
|
||||
return pid
|
||||
|
||||
except requests.exceptions.RequestException as e:
|
||||
print(f'获取作品ID:{pid}时发生网络错误:{str(e)}')
|
||||
return pid
|
||||
except Exception as e:
|
||||
print(f'处理作品ID:{pid}时发生错误:{str(e)}')
|
||||
return pid
|
||||
|
||||
def get_img(self, url):
|
||||
"""
|
||||
下载单个图片
|
||||
:param url: 原图URL,格式如:https://i.pximg.net/img-original/img/2024/12/14/20/00/36/125183562_p0.jpg
|
||||
:return: 0表示下载成功,1表示下载失败
|
||||
"""
|
||||
# 确保下载目录存在
|
||||
if not os.path.isdir('./img'):
|
||||
os.makedirs('./img')
|
||||
|
||||
# 从URL提取作品ID、页码和文件扩展名
|
||||
match = re.search(r'/(\d+)_p(\d+)\.([a-z]+)$', url)
|
||||
if not match:
|
||||
print(f'无效的URL格式: {url}')
|
||||
return 1
|
||||
|
||||
# 解析URL信息并构建文件名
|
||||
illust_id, page_num, extension = match.groups()
|
||||
file_name = f"{illust_id}_p{page_num}.{extension}"
|
||||
|
||||
# 检查Redis中是否已记录为下载
|
||||
if self.r.get(f'downloaded:{illust_id}_p{page_num}') == 'true':
|
||||
print(f'Redis记录:{file_name}已下载,跳过')
|
||||
return 0
|
||||
|
||||
# 作为备份检查,验证文件是否存在
|
||||
if os.path.isfile(f'./img/{file_name}'):
|
||||
# 如果文件存在但Redis没有记录,更新Redis记录
|
||||
self.r.set(f'downloaded:{illust_id}_p{page_num}', 'true')
|
||||
print(f'文件已存在但Redis未记录,已更新Redis:{file_name}')
|
||||
return 0
|
||||
|
||||
# 开始下载流程
|
||||
print(f'开始下载:{file_name} (第{int(page_num)+1}张)')
|
||||
t = 0 # 重试计数器
|
||||
# 最多重试3次
|
||||
while t < 3:
|
||||
try:
|
||||
# 下载图片,设置15秒超时
|
||||
img_temp = requests.get(url, headers=self.headers, timeout=15, verify=False)
|
||||
if img_temp.status_code == 200:
|
||||
break
|
||||
print(f'下载失败,状态码:{img_temp.status_code}')
|
||||
t += 1
|
||||
except requests.exceptions.RequestException as e:
|
||||
print(f'连接异常:{str(e)}')
|
||||
t += 1
|
||||
|
||||
# 如果重试3次都失败,放弃下载
|
||||
if t == 3:
|
||||
print(f'下载失败次数过多,跳过该图片')
|
||||
return 1
|
||||
|
||||
# 将图片内容写入文件
|
||||
with open(f'./img/{file_name}', 'wb') as fp:
|
||||
fp.write(img_temp.content)
|
||||
|
||||
# 下载成功后在Redis中记录
|
||||
self.r.set(f'downloaded:{illust_id}_p{page_num}', 'true')
|
||||
# 获取作品总页数并检查是否已下载所有页面
|
||||
page_count = self.r.get(f'total_pages:{illust_id}')
|
||||
if not page_count:
|
||||
# 当前页号+1可能是总页数(保守估计)
|
||||
self.r.set(f'total_pages:{illust_id}', str(int(page_num) + 1))
|
||||
elif int(page_num) + 1 == int(page_count):
|
||||
# 如果当前是最后一页,检查是否所有页面都已下载
|
||||
all_downloaded = all(
|
||||
self.r.get(f'downloaded:{illust_id}_p{i}') == 'true'
|
||||
for i in range(int(page_count))
|
||||
)
|
||||
if all_downloaded:
|
||||
self.r.set(f'downloaded:{illust_id}', 'complete')
|
||||
print(f'作品ID:{illust_id}已完全下载')
|
||||
|
||||
print(f'下载完成并已记录到Redis:{file_name}')
|
||||
return 0
|
||||
|
||||
def get_top_url(self, num):
|
||||
"""
|
||||
获取每日排行榜的特定页码数据
|
||||
:param num: 页码数(1-10)
|
||||
:return: None
|
||||
"""
|
||||
params = {
|
||||
'mode': 'daily',
|
||||
'content': 'illust',
|
||||
'p': f'{num}',
|
||||
'format': 'json'
|
||||
}
|
||||
response = requests.get(self.top_url, params=params, headers=self.headers, verify=False)
|
||||
json_data = response.json()
|
||||
self.pixiv_spider_go(json_data['contents'])
|
||||
|
||||
def get_top_pic(self):
|
||||
"""
|
||||
从排行榜数据中提取作品ID和用户ID
|
||||
并将用户ID存入Redis数据库中
|
||||
:return: 生成器,返回作品ID
|
||||
"""
|
||||
for url in self.data:
|
||||
illust_id = url['illust_id'] # 获取作品ID
|
||||
illust_user = url['user_id'] # 获取用户ID
|
||||
yield illust_id # 生成作品ID
|
||||
self.r.set(illust_id, illust_user) # 将PID保存到Redis中
|
||||
|
||||
@classmethod
|
||||
def pixiv_spider_go(cls, data):
|
||||
"""
|
||||
存储排行榜数据供后续处理
|
||||
:param data: 排行榜JSON数据中的contents部分
|
||||
"""
|
||||
cls.data = data
|
||||
|
||||
@classmethod
|
||||
def pixiv_main(cls):
|
||||
"""
|
||||
爬虫主函数
|
||||
1. 选择Redis数据库
|
||||
2. 获取或设置Cookie
|
||||
3. 配置请求头
|
||||
4. 遍历排行榜页面(1-10页)
|
||||
5. 下载每个作品的所有图片
|
||||
6. 处理下载失败的作品
|
||||
"""
|
||||
# 选择Redis数据库
|
||||
while True:
|
||||
try:
|
||||
print("\n可用的Redis数据库:")
|
||||
for i in range(6):
|
||||
print(f"{i}.DB{i}")
|
||||
db_choice = input("\n请选择Redis数据库 (0-5): ")
|
||||
db_num = int(db_choice)
|
||||
if 0 <= db_num <= 5:
|
||||
break
|
||||
print("错误:请输入0到5之间的数字")
|
||||
except ValueError:
|
||||
print("错误:请输入有效的数字")
|
||||
|
||||
global pixiv
|
||||
pixiv = PixivSpider(db_num)
|
||||
print(f"\n已选择 DB{db_num}")
|
||||
|
||||
# 从Redis获取Cookie,如果没有则要求用户输入
|
||||
cookie = pixiv.r.get('cookie')
|
||||
if not cookie:
|
||||
cookie = input('请输入一个cookie:')
|
||||
pixiv.r.set('cookie', cookie)
|
||||
|
||||
# 配置请求头,包含必要的HTTP头部信息
|
||||
cls.headers = {
|
||||
'accept': 'application/json',
|
||||
'accept-language': 'zh-CN,zh;q=0.9,zh-TW;q=0.8,en-US;q=0.7,en;q=0.6',
|
||||
'dnt': '1',
|
||||
'cookie': f'{cookie}',
|
||||
'referer': 'https://www.pixiv.net/',
|
||||
'sec-fetch-mode': 'cors',
|
||||
'sec-fetch-site': 'same-origin',
|
||||
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
|
||||
}
|
||||
|
||||
print('开始抓取...')
|
||||
# 遍历排行榜前10页
|
||||
for i in range(1, 11, 1): # p站每日排行榜最多为500个(50个/页 x 10页)
|
||||
pixiv.get_top_url(i) # 获取当前页的排行榜数据
|
||||
for j in pixiv.get_top_pic(): # 遍历当前页的所有作品
|
||||
k = pixiv.get_list(j) # 下载作品的所有图片
|
||||
if k: # 如果下载失败,将作品ID添加到错误列表
|
||||
error_list.append(k)
|
||||
|
||||
# 清理下载失败的作品记录
|
||||
for k in error_list:
|
||||
pixiv.r.delete(k)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
try:
|
||||
print('正在启动Pixiv爬虫...')
|
||||
print('确保已安装并启动Redis服务')
|
||||
print('确保已准备好有效的Pixiv Cookie')
|
||||
|
||||
# 运行主程序
|
||||
PixivSpider.pixiv_main()
|
||||
|
||||
print('爬虫运行完成')
|
||||
except redis.exceptions.ConnectionError:
|
||||
print('错误:无法连接到Redis服务,请确保Redis服务正在运行')
|
||||
except KeyboardInterrupt:
|
||||
print('\n用户中断运行')
|
||||
except Exception as e:
|
||||
print(f'发生错误:{str(e)}')
|
||||
@ -1,5 +1,7 @@
|
||||
**一个Pixiv小爬虫,目前只可以爬每日, 支持长时间爬取 跳过已经爬过的**
|
||||
|
||||
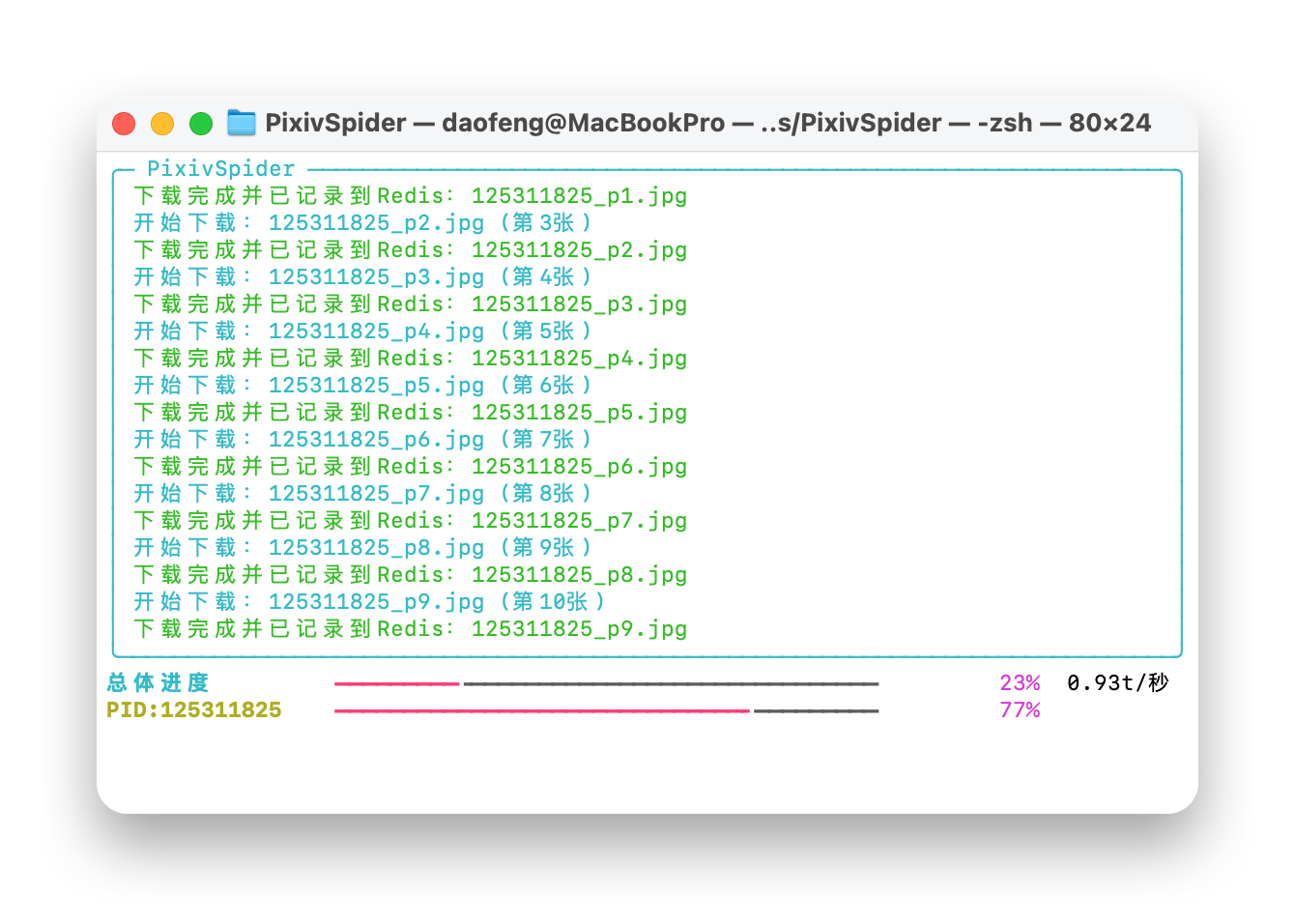
|
||||
|
||||
## 环境需求
|
||||
|
||||
Python:3.8+ / Redis
|
||||
@ -10,7 +12,7 @@ Python:3.8+ / Redis
|
||||
|
||||
```shell
|
||||
git clone https://github.com/nyaasuki/PixivSpider.git && cd ./PixivSpider
|
||||
python3 Pixiv.py
|
||||
python3 main.py
|
||||
```
|
||||
|
||||
**Windows:**
|
||||
@ -23,7 +25,7 @@ python3 Pixiv.py
|
||||
|
||||
4. 输入python+‘ ’ ←这是一个空格
|
||||
|
||||
5. 用鼠标把**Pixiv.py**这个文件拖到cmd窗口
|
||||
5. 用鼠标把**main.py**这个文件拖到cmd窗口
|
||||
|
||||
^_^
|
||||
|
||||
@ -48,8 +50,6 @@ ERROR: No matching distribution found for resquests`
|
||||
项目使用redis查重 需要安装redis
|
||||
官方安装教程:https://redis.io/docs/latest/operate/oss_and_stack/install/install-redis/
|
||||
|
||||
同时新增了一个redis快速管理小工具 能自动识别写入的数据库 提供查和删功能
|
||||
使用方法同上 运行 redis_monitor.py 即可
|
||||
## 特别提醒
|
||||
|
||||
正常来说,当没有出现上方问题时,程序出现问题大多为你的上网方式不够科学
|
||||
|
||||
44
config.py
Normal file
44
config.py
Normal file
@ -0,0 +1,44 @@
|
||||
"""配置管理"""
|
||||
from typing import Dict, Any
|
||||
from dataclasses import dataclass
|
||||
|
||||
@dataclass
|
||||
class RedisConfig:
|
||||
"""Redis配置"""
|
||||
host: str = 'localhost'
|
||||
port: int = 6379
|
||||
max_connections: int = 10
|
||||
db_range: tuple = (0, 5) # 支持的数据库范围(包含)
|
||||
|
||||
@dataclass
|
||||
class PixivConfig:
|
||||
"""Pixiv API配置"""
|
||||
ajax_url: str = 'https://www.pixiv.net/ajax/illust/{}/pages'
|
||||
top_url: str = 'https://www.pixiv.net/ranking.php'
|
||||
user_agent: str = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
|
||||
headers: Dict[str, str] = None
|
||||
|
||||
def __post_init__(self):
|
||||
"""初始化默认请求头"""
|
||||
self.headers = {
|
||||
'accept': 'application/json',
|
||||
'accept-language': 'zh-CN,zh;q=0.9,zh-TW;q=0.8,en-US;q=0.7,en;q=0.6',
|
||||
'dnt': '1',
|
||||
'referer': 'https://www.pixiv.net/',
|
||||
'sec-fetch-mode': 'cors',
|
||||
'sec-fetch-site': 'same-origin',
|
||||
'user-agent': self.user_agent
|
||||
}
|
||||
|
||||
# 全局配置实例
|
||||
REDIS_CONFIG = RedisConfig()
|
||||
PIXIV_CONFIG = PixivConfig()
|
||||
|
||||
# Redis键模式
|
||||
class RedisKeys:
|
||||
"""Redis键定义"""
|
||||
COOKIE = 'cookie'
|
||||
DOWNLOADED_IMAGE = 'downloaded:{pid}_p{page}' # 已下载的图片页
|
||||
DOWNLOADED_WORK = 'downloaded:{pid}' # 已完成的作品
|
||||
TOTAL_PAGES = 'total_pages:{pid}' # 作品总页数
|
||||
USER_ID = '{illust_id}' # 作品作者ID
|
||||
112
main.py
Normal file
112
main.py
Normal file
@ -0,0 +1,112 @@
|
||||
#!/usr/bin/env python3
|
||||
"""
|
||||
Pixiv爬虫 - 主程序入口
|
||||
环境需求:Python3.8+ / Redis
|
||||
"""
|
||||
import sys
|
||||
from typing import NoReturn
|
||||
import requests.packages.urllib3
|
||||
from rich.console import Console
|
||||
import redis.exceptions
|
||||
|
||||
from pixiv_spider import PixivSpider
|
||||
import redis_monitor
|
||||
from config import REDIS_CONFIG
|
||||
|
||||
# 禁用SSL警告
|
||||
requests.packages.urllib3.disable_warnings()
|
||||
|
||||
console = Console()
|
||||
|
||||
def show_main_menu() -> NoReturn:
|
||||
"""显示主菜单并处理用户选择"""
|
||||
while True:
|
||||
try:
|
||||
console.print("\n=== PixivSpider ===")
|
||||
console.print("1. 爬取每日排行榜")
|
||||
console.print("2. Redis数据库操作")
|
||||
console.print("3. 退出程序")
|
||||
|
||||
choice = console.input("\n请选择操作 (1-3): ")
|
||||
|
||||
if choice == "1":
|
||||
run_spider()
|
||||
elif choice == "2":
|
||||
run_redis_monitor()
|
||||
elif choice == "3":
|
||||
console.print("\n[green]再见![/green]")
|
||||
sys.exit(0)
|
||||
else:
|
||||
console.print("\n[red]无效的选择,请重试[/red]")
|
||||
|
||||
except KeyboardInterrupt:
|
||||
console.print("\n\n[yellow]检测到Ctrl+C,正在安全退出...[/yellow]")
|
||||
sys.exit(0)
|
||||
except Exception as e:
|
||||
console.print(f"\n[red]发生错误:{str(e)}[/red]")
|
||||
|
||||
def run_spider() -> None:
|
||||
"""运行Pixiv爬虫"""
|
||||
console.print("\n=== 启动PixivSpider ===")
|
||||
console.print("[yellow]确保已安装并启动Redis服务[/yellow]")
|
||||
console.print("[yellow]确保已准备好有效的Pixiv Cookie[/yellow]")
|
||||
|
||||
while True:
|
||||
try:
|
||||
console.print("\n[cyan]可用的Redis数据库:[/cyan]")
|
||||
min_db, max_db = REDIS_CONFIG.db_range
|
||||
for i in range(min_db, max_db + 1):
|
||||
console.print(f"{i}.DB{i}")
|
||||
|
||||
db_choice = console.input("\n请选择Redis数据库: ")
|
||||
db_num = int(db_choice)
|
||||
|
||||
if min_db <= db_num <= max_db:
|
||||
spider = PixivSpider(db_num)
|
||||
spider.run()
|
||||
break
|
||||
else:
|
||||
console.print(f"[red]错误:请输入{min_db}到{max_db}之间的数字[/red]")
|
||||
|
||||
except redis.exceptions.ConnectionError:
|
||||
console.print('[red]错误:无法连接到Redis服务,请确保Redis服务正在运行[/red]')
|
||||
break
|
||||
except ValueError:
|
||||
console.print("[red]错误:请输入有效的数字[/red]")
|
||||
except KeyboardInterrupt:
|
||||
console.print('\n[yellow]用户中断运行[/yellow]')
|
||||
break
|
||||
except Exception as e:
|
||||
console.print(f'[red]发生错误:{str(e)}[/red]')
|
||||
break
|
||||
|
||||
def run_redis_monitor() -> None:
|
||||
"""运行Redis管理工具"""
|
||||
console.print("\n=== 启动Redis管理工具 ===")
|
||||
redis_monitor.show_menu()
|
||||
|
||||
def check_dependencies() -> None:
|
||||
"""检查并安装依赖包"""
|
||||
try:
|
||||
import redis
|
||||
import requests
|
||||
from rich import console, progress, layout, panel
|
||||
except ImportError:
|
||||
console.print('[yellow]检测到缺少必要包!正在尝试安装!.....[/yellow]')
|
||||
import os
|
||||
os.system('pip install -r requirements.txt')
|
||||
|
||||
# 重新导入以验证安装
|
||||
import redis
|
||||
import requests
|
||||
from rich import console, progress, layout, panel
|
||||
|
||||
console.print('[green]依赖安装完成[/green]')
|
||||
|
||||
if __name__ == "__main__":
|
||||
try:
|
||||
check_dependencies()
|
||||
show_main_menu()
|
||||
except Exception as e:
|
||||
console.print(f"[red]程序启动失败:{str(e)}[/red]")
|
||||
sys.exit(1)
|
||||
150
pixiv_download.py
Normal file
150
pixiv_download.py
Normal file
@ -0,0 +1,150 @@
|
||||
"""Pixiv下载组件"""
|
||||
import os
|
||||
import re
|
||||
from typing import Optional, Union
|
||||
import requests
|
||||
from rich.progress import Progress
|
||||
|
||||
from config import PIXIV_CONFIG
|
||||
from redis_client import RedisClient
|
||||
|
||||
class PixivDownloader:
|
||||
"""处理Pixiv图片下载"""
|
||||
|
||||
def __init__(self, headers: dict, progress: Progress):
|
||||
"""
|
||||
初始化下载器
|
||||
|
||||
参数:
|
||||
headers: 带cookie的请求头
|
||||
progress: Rich进度条实例
|
||||
"""
|
||||
self.headers = headers
|
||||
self.progress = progress
|
||||
self.redis = RedisClient()
|
||||
|
||||
def download_image(self, url: str) -> bool:
|
||||
"""
|
||||
下载单张图片
|
||||
|
||||
参数:
|
||||
url: 图片URL
|
||||
|
||||
返回:
|
||||
bool: 成功返回True,失败返回False
|
||||
"""
|
||||
# 从URL提取图片信息
|
||||
match = re.search(r'/(\d+)_p(\d+)\.([a-z]+)$', url)
|
||||
if not match:
|
||||
return False
|
||||
|
||||
illust_id, page_num, extension = match.groups()
|
||||
file_name = f"{illust_id}_p{page_num}.{extension}"
|
||||
|
||||
# 检查是否已下载
|
||||
if self.redis.is_image_downloaded(illust_id, page_num):
|
||||
return True
|
||||
|
||||
# 确保下载目录存在
|
||||
if not os.path.isdir('./img'):
|
||||
os.makedirs('./img')
|
||||
|
||||
# 下载重试机制
|
||||
for attempt in range(3):
|
||||
try:
|
||||
response = requests.get(
|
||||
url,
|
||||
headers=self.headers,
|
||||
timeout=15,
|
||||
verify=False
|
||||
)
|
||||
if response.status_code == 200:
|
||||
# 保存图片
|
||||
with open(f'./img/{file_name}', 'wb') as fp:
|
||||
fp.write(response.content)
|
||||
|
||||
# 更新Redis记录
|
||||
self.redis.mark_image_downloaded(illust_id, page_num)
|
||||
|
||||
# 更新总页数
|
||||
total_pages = self.redis.get_total_pages(illust_id)
|
||||
if not total_pages:
|
||||
self.redis.set_total_pages(illust_id, int(page_num) + 1)
|
||||
elif int(page_num) + 1 == total_pages:
|
||||
# 检查作品是否完成
|
||||
all_downloaded = all(
|
||||
self.redis.is_image_downloaded(illust_id, i)
|
||||
for i in range(total_pages)
|
||||
)
|
||||
if all_downloaded:
|
||||
self.redis.mark_work_complete(illust_id)
|
||||
|
||||
return True
|
||||
|
||||
except requests.RequestException:
|
||||
if attempt == 2: # 最后一次尝试失败
|
||||
return False
|
||||
continue
|
||||
|
||||
return False
|
||||
|
||||
def download_work(self, work_id: str) -> bool:
|
||||
"""
|
||||
下载作品的所有图片
|
||||
|
||||
参数:
|
||||
work_id: Pixiv作品ID
|
||||
|
||||
返回:
|
||||
bool: 全部成功返回True,否则False
|
||||
"""
|
||||
# 跳过已完成的作品
|
||||
if self.redis.is_work_complete(work_id):
|
||||
return True
|
||||
|
||||
try:
|
||||
# 获取图片URL列表
|
||||
response = requests.get(
|
||||
PIXIV_CONFIG.ajax_url.format(work_id),
|
||||
headers=self.headers,
|
||||
verify=False
|
||||
)
|
||||
data = response.json()
|
||||
|
||||
if data.get('error'):
|
||||
return False
|
||||
|
||||
images = data.get('body', [])
|
||||
if not images:
|
||||
return False
|
||||
|
||||
# 下载每张图片
|
||||
if len(images) > 1:
|
||||
# 多图作品
|
||||
subtask_id = self.progress.add_task(
|
||||
f"[yellow]PID:{work_id}",
|
||||
total=len(images)
|
||||
)
|
||||
|
||||
success = True
|
||||
for image in images:
|
||||
if 'urls' not in image or 'original' not in image['urls']:
|
||||
success = False
|
||||
continue
|
||||
|
||||
if not self.download_image(image['urls']['original']):
|
||||
success = False
|
||||
|
||||
self.progress.update(subtask_id, advance=1)
|
||||
|
||||
self.progress.remove_task(subtask_id)
|
||||
return success
|
||||
|
||||
else:
|
||||
# 单图作品
|
||||
if 'urls' not in images[0] or 'original' not in images[0]['urls']:
|
||||
return False
|
||||
return self.download_image(images[0]['urls']['original'])
|
||||
|
||||
except (requests.RequestException, KeyError, ValueError):
|
||||
return False
|
||||
167
pixiv_spider.py
Normal file
167
pixiv_spider.py
Normal file
@ -0,0 +1,167 @@
|
||||
"""
|
||||
Pixiv爬虫 - 每日排行榜下载
|
||||
环境需求:Python3.8+ / Redis
|
||||
"""
|
||||
from typing import Generator, List, Dict, Any
|
||||
import requests
|
||||
from rich.console import Console
|
||||
from rich.progress import (
|
||||
Progress,
|
||||
BarColumn,
|
||||
TaskProgressColumn,
|
||||
TextColumn,
|
||||
SpinnerColumn
|
||||
)
|
||||
from rich.live import Live
|
||||
from rich.layout import Layout
|
||||
from rich.panel import Panel
|
||||
from rich.console import Group
|
||||
|
||||
from config import PIXIV_CONFIG
|
||||
from redis_client import RedisClient
|
||||
from pixiv_download import PixivDownloader
|
||||
|
||||
requests.packages.urllib3.disable_warnings()
|
||||
|
||||
class PixivSpider:
|
||||
"""Pixiv每日排行榜爬虫"""
|
||||
|
||||
TOTAL_IMAGES = 500 # 每日排行榜总图片数
|
||||
|
||||
def __init__(self, db: int = 0):
|
||||
"""
|
||||
初始化爬虫
|
||||
|
||||
参数:
|
||||
db: Redis数据库编号(0-5)
|
||||
"""
|
||||
# 设置Redis
|
||||
self.redis = RedisClient()
|
||||
if not self.redis.select_db(db):
|
||||
raise ValueError(f"无效的Redis数据库编号: {db}")
|
||||
|
||||
# 设置界面组件
|
||||
self.console = Console()
|
||||
self._setup_ui()
|
||||
|
||||
# 初始化状态
|
||||
self.headers = None
|
||||
self.current_ranking_data = []
|
||||
self.failed_works = []
|
||||
|
||||
def _setup_ui(self) -> None:
|
||||
"""设置Rich界面组件"""
|
||||
# 创建布局
|
||||
self.layout = Layout()
|
||||
self.layout.split(
|
||||
Layout(name="PixivSpider", ratio=8),
|
||||
Layout(name="progress", ratio=2)
|
||||
)
|
||||
|
||||
# 创建进度条
|
||||
self.progress = Progress(
|
||||
TextColumn("[bold blue]{task.description}"),
|
||||
BarColumn(bar_width=40),
|
||||
TaskProgressColumn(),
|
||||
TextColumn("{task.fields[speed]}"),
|
||||
console=Console(stderr=True),
|
||||
expand=True
|
||||
)
|
||||
|
||||
# 设置日志面板
|
||||
self.log_messages = []
|
||||
self.main_task_id = self.progress.add_task(
|
||||
"[cyan]总体进度",
|
||||
total=self.TOTAL_IMAGES,
|
||||
speed=""
|
||||
)
|
||||
|
||||
def _update_log(self, message: str) -> None:
|
||||
"""更新日志显示"""
|
||||
self.log_messages.append(message)
|
||||
if len(self.log_messages) > 18:
|
||||
self.log_messages.pop(0)
|
||||
log_group = Group(*self.log_messages)
|
||||
self.layout["PixivSpider"].update(
|
||||
Panel(
|
||||
log_group,
|
||||
title="PixivSpider",
|
||||
title_align="left",
|
||||
border_style="cyan",
|
||||
padding=(0, 1)
|
||||
)
|
||||
)
|
||||
|
||||
def _setup_session(self) -> None:
|
||||
"""设置请求会话"""
|
||||
cookie = self.redis.get_cookie()
|
||||
if not cookie:
|
||||
cookie = input('请输入一个cookie:')
|
||||
self.redis.set_cookie(cookie)
|
||||
|
||||
self.headers = PIXIV_CONFIG.headers.copy()
|
||||
self.headers['cookie'] = cookie
|
||||
|
||||
def get_ranking_page(self, page: int) -> None:
|
||||
"""
|
||||
获取排行榜单页数据
|
||||
|
||||
参数:
|
||||
page: 页码(1-10)
|
||||
"""
|
||||
params = {
|
||||
'mode': 'daily',
|
||||
'content': 'illust',
|
||||
'p': str(page),
|
||||
'format': 'json'
|
||||
}
|
||||
|
||||
response = requests.get(
|
||||
PIXIV_CONFIG.top_url,
|
||||
params=params,
|
||||
headers=self.headers,
|
||||
verify=False
|
||||
)
|
||||
data = response.json()
|
||||
self.current_ranking_data = data['contents']
|
||||
|
||||
def process_ranking_data(self) -> Generator[str, None, None]:
|
||||
"""
|
||||
处理当前排行榜数据
|
||||
|
||||
生成:
|
||||
str: 作品ID
|
||||
"""
|
||||
for item in self.current_ranking_data:
|
||||
work_id = str(item['illust_id'])
|
||||
user_id = str(item['user_id'])
|
||||
self.redis.store_user_id(work_id, user_id)
|
||||
yield work_id
|
||||
|
||||
def run(self) -> None:
|
||||
"""运行爬虫"""
|
||||
self._setup_session()
|
||||
downloader = PixivDownloader(self.headers, self.progress)
|
||||
|
||||
with Live(self.layout, self.console, refresh_per_second=10):
|
||||
self.layout["progress"].update(self.progress)
|
||||
self._update_log('[cyan]开始抓取...[/cyan]')
|
||||
|
||||
# 处理排行榜页面
|
||||
for page in range(1, 11):
|
||||
try:
|
||||
self.get_ranking_page(page)
|
||||
for work_id in self.process_ranking_data():
|
||||
if not downloader.download_work(work_id):
|
||||
self.failed_works.append(work_id)
|
||||
self.progress.update(self.main_task_id, advance=1)
|
||||
|
||||
except requests.RequestException as e:
|
||||
self._update_log(f'[red]获取排行榜第{page}页时发生错误:{str(e)}[/red]')
|
||||
continue
|
||||
|
||||
# 清理失败作品的记录
|
||||
for work_id in self.failed_works:
|
||||
self.redis.client.delete(work_id)
|
||||
|
||||
self._update_log('[green]爬虫运行完成[/green]')
|
||||
132
redis_client.py
Normal file
132
redis_client.py
Normal file
@ -0,0 +1,132 @@
|
||||
"""Redis客户端管理"""
|
||||
from typing import Optional
|
||||
import redis
|
||||
from redis.connection import ConnectionPool
|
||||
from config import REDIS_CONFIG, RedisKeys
|
||||
|
||||
class RedisClient:
|
||||
"""Redis客户端管理器,使用连接池"""
|
||||
_pools: dict[int, ConnectionPool] = {}
|
||||
_instance: Optional['RedisClient'] = None
|
||||
|
||||
def __new__(cls) -> 'RedisClient':
|
||||
"""确保单例"""
|
||||
if cls._instance is None:
|
||||
cls._instance = super().__new__(cls)
|
||||
return cls._instance
|
||||
|
||||
def __init__(self):
|
||||
"""初始化客户端管理器"""
|
||||
if not hasattr(self, '_initialized'):
|
||||
self._initialized = True
|
||||
self._current_db = 0
|
||||
self._redis: Optional[redis.Redis] = None
|
||||
self._init_connection()
|
||||
|
||||
def _get_pool(self, db: int) -> ConnectionPool:
|
||||
"""获取指定数据库的连接池"""
|
||||
if db not in self._pools:
|
||||
self._pools[db] = redis.ConnectionPool(
|
||||
host=REDIS_CONFIG.host,
|
||||
port=REDIS_CONFIG.port,
|
||||
db=db,
|
||||
max_connections=REDIS_CONFIG.max_connections,
|
||||
decode_responses=True
|
||||
)
|
||||
return self._pools[db]
|
||||
|
||||
def _init_connection(self) -> None:
|
||||
"""初始化当前数据库的连接"""
|
||||
self._redis = redis.Redis(
|
||||
connection_pool=self._get_pool(self._current_db)
|
||||
)
|
||||
|
||||
def select_db(self, db: int) -> bool:
|
||||
"""
|
||||
切换到指定数据库
|
||||
|
||||
参数:
|
||||
db: 数据库编号
|
||||
|
||||
返回:
|
||||
bool: 成功返回True,失败返回False
|
||||
"""
|
||||
min_db, max_db = REDIS_CONFIG.db_range
|
||||
if not min_db <= db <= max_db:
|
||||
return False
|
||||
|
||||
if db != self._current_db:
|
||||
self._current_db = db
|
||||
self._init_connection()
|
||||
return True
|
||||
|
||||
@property
|
||||
def client(self) -> redis.Redis:
|
||||
"""获取当前Redis客户端"""
|
||||
return self._redis
|
||||
|
||||
def get_cookie(self) -> Optional[str]:
|
||||
"""获取存储的Pixiv cookie"""
|
||||
return self._redis.get(RedisKeys.COOKIE)
|
||||
|
||||
def set_cookie(self, cookie: str) -> None:
|
||||
"""存储Pixiv cookie"""
|
||||
self._redis.set(RedisKeys.COOKIE, cookie)
|
||||
|
||||
def is_image_downloaded(self, pid: str, page: int) -> bool:
|
||||
"""检查特定图片页是否已下载"""
|
||||
key = RedisKeys.DOWNLOADED_IMAGE.format(pid=pid, page=page)
|
||||
return self._redis.get(key) == 'true'
|
||||
|
||||
def mark_image_downloaded(self, pid: str, page: int) -> None:
|
||||
"""标记特定图片页为已下载"""
|
||||
key = RedisKeys.DOWNLOADED_IMAGE.format(pid=pid, page=page)
|
||||
self._redis.set(key, 'true')
|
||||
|
||||
def is_work_complete(self, pid: str) -> bool:
|
||||
"""检查作品是否已完全下载"""
|
||||
key = RedisKeys.DOWNLOADED_WORK.format(pid=pid)
|
||||
return self._redis.get(key) == 'complete'
|
||||
|
||||
def mark_work_complete(self, pid: str) -> None:
|
||||
"""标记作品为已完全下载"""
|
||||
key = RedisKeys.DOWNLOADED_WORK.format(pid=pid)
|
||||
self._redis.set(key, 'complete')
|
||||
|
||||
def get_total_pages(self, pid: str) -> Optional[int]:
|
||||
"""获取作品总页数"""
|
||||
key = RedisKeys.TOTAL_PAGES.format(pid=pid)
|
||||
value = self._redis.get(key)
|
||||
return int(value) if value else None
|
||||
|
||||
def set_total_pages(self, pid: str, total: int) -> None:
|
||||
"""设置作品总页数"""
|
||||
key = RedisKeys.TOTAL_PAGES.format(pid=pid)
|
||||
self._redis.set(key, str(total))
|
||||
|
||||
def store_user_id(self, illust_id: str, user_id: str) -> None:
|
||||
"""存储作品作者ID"""
|
||||
key = RedisKeys.USER_ID.format(illust_id=illust_id)
|
||||
self._redis.set(key, user_id)
|
||||
|
||||
def get_db_stats(self) -> tuple[int, list[str]]:
|
||||
"""
|
||||
获取当前数据库统计信息
|
||||
|
||||
返回:
|
||||
tuple: (作品数量, 作品ID列表)
|
||||
"""
|
||||
pattern = RedisKeys.DOWNLOADED_IMAGE.format(pid='*', page='0')
|
||||
work_keys = self._redis.keys(pattern)
|
||||
work_ids = [key.split(':')[1].split('_')[0] for key in work_keys]
|
||||
return len(work_ids), work_ids
|
||||
|
||||
def clear_db(self) -> None:
|
||||
"""清空当前数据库"""
|
||||
self._redis.flushdb()
|
||||
|
||||
def close(self) -> None:
|
||||
"""关闭所有连接池"""
|
||||
for pool in self._pools.values():
|
||||
pool.disconnect()
|
||||
self._pools.clear()
|
||||
287
redis_monitor.py
287
redis_monitor.py
@ -1,160 +1,173 @@
|
||||
import redis
|
||||
"""Redis监控和管理工具"""
|
||||
from typing import Optional, Dict
|
||||
import sys
|
||||
from rich.console import Console
|
||||
from rich.table import Table
|
||||
from rich.prompt import Prompt, Confirm
|
||||
|
||||
def show_db_status(r, db_index):
|
||||
"""显示指定数据库的状态信息"""
|
||||
try:
|
||||
# 切换到指定数据库
|
||||
r.select(db_index)
|
||||
from redis_client import RedisClient
|
||||
from config import REDIS_CONFIG
|
||||
|
||||
# 检查并显示Cookie状态
|
||||
cookie = r.get('cookie')
|
||||
if cookie:
|
||||
print(f"Cookie值: {cookie}")
|
||||
else:
|
||||
print("Cookie状态: 匿名")
|
||||
console = Console()
|
||||
|
||||
# 获取所有键
|
||||
all_keys = r.keys('*')
|
||||
class RedisMonitor:
|
||||
"""Redis监控和管理界面"""
|
||||
|
||||
# 统计图片ID数量
|
||||
pid_count = len([key for key in all_keys if key.startswith('downloaded:') and '_p0' in key])
|
||||
print(f"当前存储的图片作品数量: {pid_count}\n")
|
||||
except redis.RedisError as e:
|
||||
print(f"错误:{str(e)}")
|
||||
def __init__(self):
|
||||
"""初始化监控器"""
|
||||
self.redis = RedisClient()
|
||||
|
||||
def check_redis_status():
|
||||
"""检查Redis状态并显示详细信息"""
|
||||
try:
|
||||
# 连接到Redis
|
||||
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
|
||||
def _show_db_info(self, db_index: int) -> None:
|
||||
"""
|
||||
显示数据库详细信息
|
||||
|
||||
# 检查连接
|
||||
r.ping()
|
||||
参数:
|
||||
db_index: 数据库编号
|
||||
"""
|
||||
try:
|
||||
self.redis.select_db(db_index)
|
||||
|
||||
# 获取活跃数据库信息(仅0-5)
|
||||
info = r.info()
|
||||
keyspace_info = {k: v for k, v in info.items() if k.startswith('db')}
|
||||
table = Table(title=f"数据库 db{db_index} 信息")
|
||||
table.add_column("项目", style="cyan")
|
||||
table.add_column("值", style="green")
|
||||
|
||||
# 过滤0-5范围内的数据库
|
||||
valid_indices = set(range(6)) # 0-5
|
||||
db_indices = [int(k.replace('db', '')) for k in keyspace_info.keys() if int(k.replace('db', '')) in valid_indices]
|
||||
db_indices.sort()
|
||||
# Cookie状态
|
||||
cookie = self.redis.get_cookie()
|
||||
table.add_row(
|
||||
"Cookie状态",
|
||||
cookie[:30] + "..." if cookie else "未设置"
|
||||
)
|
||||
|
||||
if not db_indices:
|
||||
print("\n当前没有活跃的数据库")
|
||||
return
|
||||
db_list = ', '.join([f"db{i}" for i in db_indices])
|
||||
print(f"\n活跃的Redis数据库: {db_list}")
|
||||
# 作品统计
|
||||
work_count, work_ids = self.redis.get_db_stats()
|
||||
table.add_row("已下载作品数", str(work_count))
|
||||
|
||||
if len(db_indices) == 1:
|
||||
# 只有一个数据库,直接显示其信息
|
||||
print(f"\n数据库 db{db_indices[0]} 的信息:")
|
||||
show_db_status(r, db_indices[0])
|
||||
else:
|
||||
# 多个数据库,让用户选择
|
||||
while True:
|
||||
choice = input("\n请选择要查看的数据库编号 (例如: 0 表示db0): ")
|
||||
try:
|
||||
db_index = int(choice)
|
||||
if db_index in db_indices:
|
||||
print(f"\n数据库 db{db_index} 的信息:")
|
||||
show_db_status(r, db_index)
|
||||
break
|
||||
else:
|
||||
print("无效的数据库编号,请重试")
|
||||
except ValueError:
|
||||
print("请输入有效的数字")
|
||||
console.print(table)
|
||||
|
||||
except redis.ConnectionError:
|
||||
print("错误:无法连接到Redis服务器,请确保Redis服务正在运行")
|
||||
except Exception as e:
|
||||
print(f"错误:{str(e)}")
|
||||
except Exception as e:
|
||||
console.print(f"[red]获取数据库信息时出错:{str(e)}[/red]")
|
||||
|
||||
def clear_redis_db():
|
||||
"""清空Redis数据库"""
|
||||
try:
|
||||
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
|
||||
# 获取当前数据库信息(仅0-5)
|
||||
info = r.info()
|
||||
keyspace_info = {k: v for k, v in info.items() if k.startswith('db')}
|
||||
def show_status(self) -> None:
|
||||
"""显示Redis状态和数据库信息"""
|
||||
try:
|
||||
# 获取活跃数据库
|
||||
active_dbs = []
|
||||
min_db, max_db = REDIS_CONFIG.db_range
|
||||
for db in range(min_db, max_db + 1):
|
||||
if self.redis.select_db(db):
|
||||
work_count, _ = self.redis.get_db_stats()
|
||||
if work_count > 0:
|
||||
active_dbs.append(db)
|
||||
|
||||
# 过滤0-5范围内的数据库
|
||||
valid_indices = set(range(6)) # 0-5
|
||||
db_indices = [int(k.replace('db', '')) for k in keyspace_info.keys() if int(k.replace('db', '')) in valid_indices]
|
||||
db_indices.sort()
|
||||
if not active_dbs:
|
||||
console.print("\n[yellow]当前没有活跃的数据库[/yellow]")
|
||||
return
|
||||
|
||||
if not db_indices:
|
||||
print("\n当前没有活跃的数据库")
|
||||
return
|
||||
db_list = ', '.join([f"db{i}" for i in db_indices])
|
||||
print(f"\n活跃的Redis数据库: {db_list}")
|
||||
print("\n清空选项:")
|
||||
print("1. 清空指定数据库")
|
||||
print("2. 清空所有数据库")
|
||||
print("3. 取消操作")
|
||||
# 显示数据库列表
|
||||
db_list = ", ".join(f"db{db}" for db in active_dbs)
|
||||
console.print(f"\n[cyan]活跃的数据库: {db_list}[/cyan]")
|
||||
|
||||
choice = input("请选择操作 (1-3): ")
|
||||
|
||||
if choice == '1':
|
||||
if len(db_indices) == 1:
|
||||
db_index = db_indices[0]
|
||||
confirm = input(f"确定要清空数据库 db{db_index} 吗?(y/n): ")
|
||||
if confirm.lower() == 'y':
|
||||
r.select(db_index)
|
||||
r.flushdb()
|
||||
print(f"数据库 db{db_index} 已清空\n")
|
||||
# 显示详细信息
|
||||
if len(active_dbs) == 1:
|
||||
self._show_db_info(active_dbs[0])
|
||||
else:
|
||||
while True:
|
||||
choice = input("\n请选择要清空的数据库编号 (例如: 0 表示db0): ")
|
||||
try:
|
||||
db_index = int(choice)
|
||||
if 0 <= db_index <= 5 and db_index in db_indices:
|
||||
confirm = input(f"确定要清空数据库 db{db_index} 吗?(y/n): ")
|
||||
if confirm.lower() == 'y':
|
||||
r.select(db_index)
|
||||
r.flushdb()
|
||||
print(f"数据库 db{db_index} 已清空\n")
|
||||
break
|
||||
else:
|
||||
print("无效的数据库编号,请重试")
|
||||
except ValueError:
|
||||
print("请输入有效的数字")
|
||||
db = Prompt.ask(
|
||||
"请选择要查看的数据库编号",
|
||||
choices=[str(db) for db in active_dbs]
|
||||
)
|
||||
self._show_db_info(int(db))
|
||||
break
|
||||
|
||||
elif choice == '2':
|
||||
confirm = input("确定要清空所有数据库吗?(y/n): ")
|
||||
if confirm.lower() == 'y':
|
||||
for db_index in range(6): # 0-5
|
||||
r.select(db_index)
|
||||
r.flushdb()
|
||||
print("所有的数据库已清空\n")
|
||||
elif choice == '3':
|
||||
print("已取消操作\n")
|
||||
else:
|
||||
print("无效的选择\n")
|
||||
except Exception as e:
|
||||
console.print(f"[red]获取Redis状态时出错:{str(e)}[/red]")
|
||||
|
||||
except redis.ConnectionError:
|
||||
print("错误:无法连接到Redis服务器,请确保Redis服务正在运行")
|
||||
def clear_database(self) -> None:
|
||||
"""清空Redis数据库"""
|
||||
try:
|
||||
# 获取活跃数据库
|
||||
active_dbs = []
|
||||
min_db, max_db = REDIS_CONFIG.db_range
|
||||
for db in range(min_db, max_db + 1):
|
||||
if self.redis.select_db(db):
|
||||
work_count, _ = self.redis.get_db_stats()
|
||||
if work_count > 0:
|
||||
active_dbs.append(db)
|
||||
|
||||
if not active_dbs:
|
||||
console.print("\n[yellow]当前没有活跃的数据库[/yellow]")
|
||||
return
|
||||
|
||||
# 显示数据库列表
|
||||
db_list = ", ".join(f"db{db}" for db in active_dbs)
|
||||
console.print(f"\n[cyan]活跃的数据库: {db_list}[/cyan]")
|
||||
|
||||
# 显示选项
|
||||
console.print("\n清空选项:")
|
||||
console.print("1. 清空指定数据库")
|
||||
console.print("2. 清空所有数据库")
|
||||
console.print("3. 取消操作")
|
||||
|
||||
choice = Prompt.ask("请选择操作", choices=["1", "2", "3"])
|
||||
|
||||
if choice == "1":
|
||||
if len(active_dbs) == 1:
|
||||
db = active_dbs[0]
|
||||
if Confirm.ask(f"确定要清空数据库 db{db} 吗?"):
|
||||
self.redis.select_db(db)
|
||||
self.redis.clear_db()
|
||||
console.print(f"[green]数据库 db{db} 已清空[/green]")
|
||||
else:
|
||||
db = int(Prompt.ask(
|
||||
"请选择要清空的数据库编号",
|
||||
choices=[str(db) for db in active_dbs]
|
||||
))
|
||||
if Confirm.ask(f"确定要清空数据库 db{db} 吗?"):
|
||||
self.redis.select_db(db)
|
||||
self.redis.clear_db()
|
||||
console.print(f"[green]数据库 db{db} 已清空[/green]")
|
||||
|
||||
elif choice == "2":
|
||||
if Confirm.ask("确定要清空所有数据库吗?"):
|
||||
for db in range(min_db, max_db + 1):
|
||||
self.redis.select_db(db)
|
||||
self.redis.clear_db()
|
||||
console.print("[green]所有数据库已清空[/green]")
|
||||
|
||||
except Exception as e:
|
||||
console.print(f"[red]清空数据库时出错:{str(e)}[/red]")
|
||||
|
||||
def run(self) -> None:
|
||||
"""运行监控界面"""
|
||||
while True:
|
||||
console.print("\n=== Redis管理工具 ===")
|
||||
console.print("1. 显示状态")
|
||||
console.print("2. 清空数据库")
|
||||
console.print("3. 退出")
|
||||
|
||||
try:
|
||||
choice = Prompt.ask("请选择操作", choices=["1", "2", "3"])
|
||||
|
||||
if choice == "1":
|
||||
self.show_status()
|
||||
elif choice == "2":
|
||||
self.clear_database()
|
||||
else:
|
||||
break
|
||||
|
||||
except KeyboardInterrupt:
|
||||
console.print("\n[yellow]用户中断操作[/yellow]")
|
||||
break
|
||||
except Exception as e:
|
||||
console.print(f"[red]发生错误:{str(e)}[/red]")
|
||||
|
||||
def show_menu() -> None:
|
||||
"""Redis监控入口"""
|
||||
try:
|
||||
monitor = RedisMonitor()
|
||||
monitor.run()
|
||||
except Exception as e:
|
||||
print(f"错误:{str(e)}")
|
||||
|
||||
def show_menu():
|
||||
"""显示交互菜单"""
|
||||
while True:
|
||||
print("=== Redis管理工具 ===")
|
||||
print("1. 显示状态")
|
||||
print("2. 清空数据库")
|
||||
print("3. 退出")
|
||||
choice = input("请选择操作 (1-3): ")
|
||||
|
||||
if choice == '1':
|
||||
check_redis_status()
|
||||
elif choice == '2':
|
||||
clear_redis_db()
|
||||
elif choice == '3':
|
||||
print("退出程序")
|
||||
break
|
||||
else:
|
||||
print("无效的选择,请重试\n")
|
||||
console.print(f"[red]启动Redis管理工具时出错:{str(e)}[/red]")
|
||||
|
||||
if __name__ == '__main__':
|
||||
show_menu()
|
||||
|
||||
@ -1,2 +1,4 @@
|
||||
redis==5.2.1
|
||||
requests==2.32.3
|
||||
rich==13.7.1
|
||||
urllib3<2.0.0 # 确保与requests兼容
|
||||
|
||||
Loading…
Reference in New Issue
Block a user