Compare commits
46 Commits
8a6fe2e7aa
...
c45e2bd7f9
| Author | SHA1 | Date |
|---|---|---|
|
|
c45e2bd7f9 | |
|
|
016e8754b9 | |
|
|
8d5c34601b | |
|
|
4e8e235024 | |
|
|
53051852f1 | |
|
|
49434901d8 | |
|
|
f6fa0c9cd9 | |
|
|
c3e65cdf96 | |
|
|
26e2805f0e | |
|
|
4f7b6b2b9e | |
|
|
bb4d185a57 | |
|
|
b8bc2b6d60 | |
|
|
2d0307dc6a | |
|
|
e88c713895 | |
|
|
c1838623d4 | |
|
|
9d3bd6f6d7 | |
|
|
322ce9b940 | |
|
|
c2ab680e18 | |
|
|
0de6505324 | |
|
|
f3281d1e37 | |
|
|
f2e18f1366 | |
|
|
50890e4f44 | |
|
|
cd051e345b | |
|
|
57cb626334 | |
|
|
b9fbce73a9 | |
|
|
1ff9e8c3e6 | |
|
|
1669821386 | |
|
|
f54ceb4dc4 | |
|
|
4cf6ed50cb | |
|
|
43b5be3189 | |
|
|
4769472ba2 | |
|
|
cbdab9c0c9 | |
|
|
8f31203b46 | |
|
|
d766298065 | |
|
|
6bc929abea | |
|
|
443a04bc66 | |
|
|
c90b252e94 | |
|
|
e56584c6e2 | |
|
|
1b680a9690 | |
|
|
8bd34d1881 | |
|
|
1ff1a183ea | |
|
|
5449f84f06 | |
|
|
997a956f4f | |
|
|
9ebe62b3e9 | |
|
|
c478586872 | |
|
|
350a9b49b8 |
|
|
@ -33,4 +33,4 @@ jobs:
|
|||
python infer/modules/train/preprocess.py logs/mute/0_gt_wavs 48000 8 logs/mi-test True 3.7
|
||||
touch logs/mi-test/extract_f0_feature.log
|
||||
python infer/modules/train/extract/extract_f0_print.py logs/mi-test $(nproc) pm
|
||||
python infer/modules/train/extract_feature_print.py cpu 1 0 0 logs/mi-test v1
|
||||
python infer/modules/train/extract_feature_print.py cpu 1 0 0 logs/mi-test v1 True
|
||||
|
|
|
|||
|
|
@ -21,3 +21,8 @@ rmvpe.pt
|
|||
|
||||
# To set a Python version for the project
|
||||
.tool-versions
|
||||
|
||||
/runtime
|
||||
/assets/weights/*
|
||||
ffmpeg.*
|
||||
ffprobe.*
|
||||
|
|
@ -0,0 +1,11 @@
|
|||
# 贡献规则
|
||||
1. 一般来说,作者`@RVC-Boss`将拒绝所有的算法更改,除非它是为了修复某个代码层面的错误或警告
|
||||
2. 您可以贡献本仓库的其他位置,如翻译和WebUI,但请尽量作最小更改
|
||||
3. 所有更改都需要由`@RVC-Boss`批准,因此您的PR可能会被搁置
|
||||
4. 由此带来的不便请您谅解
|
||||
|
||||
# Contributing Rules
|
||||
1. Generally, the author `@RVC-Boss` will reject all algorithm changes unless what is to fix a code-level error or warning.
|
||||
2. You can contribute to other parts of this repo like translations and WebUI, but please minimize your changes as much as possible.
|
||||
3. All changes need to be approved by `@RVC-Boss`, so your PR may be put on hold.
|
||||
4. Please accept our apologies for any inconvenience caused.
|
||||
190
README.md
190
README.md
|
|
@ -16,26 +16,33 @@
|
|||
|
||||
[**更新日志**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**常见问题解答**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
|
||||
|
||||
[**English**](./docs/en/README.en.md) | [**中文简体**](./README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Français**](./docs/fr/README.fr.md) | [**Türkçe**](./docs/tr/README.tr.md)
|
||||
|
||||
</div>
|
||||
|
||||
------
|
||||
|
||||
[**English**](./docs/en/README.en.md) | [**中文简体**](./README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Français**](./docs/fr/README.fr.md)| [**Türkçe**](./docs/tr/README.tr.md)
|
||||
|
||||
点此查看我们的[演示视频](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
||||
|
||||
训练推理界面:go-web.bat
|
||||
|
||||
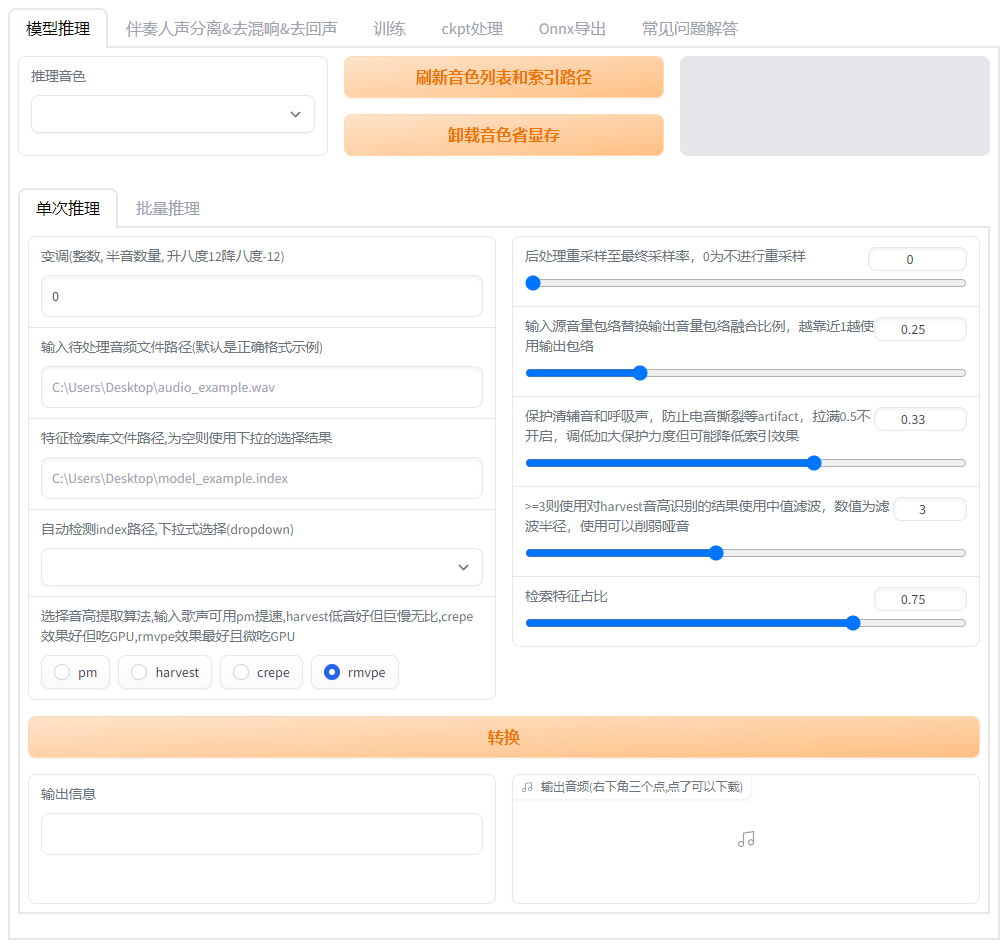
|
||||
|
||||
实时变声界面:go-realtime-gui.bat
|
||||
|
||||
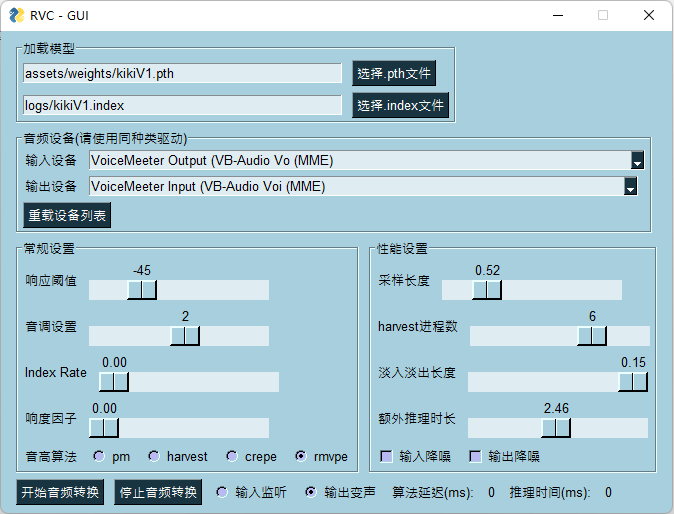
|
||||
|
||||
> 底模使用接近50小时的开源高质量VCTK训练集训练,无版权方面的顾虑,请大家放心使用
|
||||
|
||||
> 请期待RVCv3的底模,参数更大,数据更大,效果更好,基本持平的推理速度,需要训练数据量更少。
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td align="center">训练推理界面</td>
|
||||
<td align="center">实时变声界面</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/092e5c12-0d49-4168-a590-0b0ef6a4f630"></td>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/730b4114-8805-44a1-ab1a-04668f3c30a6"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">go-web.bat</td>
|
||||
<td align="center">go-realtime-gui.bat</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">可以自由选择想要执行的操作。</td>
|
||||
<td align="center">我们已经实现端到端170ms延迟。如使用ASIO输入输出设备,已能实现端到端90ms延迟,但非常依赖硬件驱动支持。</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## 简介
|
||||
本仓库具有以下特点
|
||||
+ 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
|
||||
|
|
@ -47,47 +54,55 @@
|
|||
+ 使用最先进的[人声音高提取算法InterSpeech2023-RMVPE](#参考项目)根绝哑音问题。效果最好(显著地)但比crepe_full更快、资源占用更小
|
||||
+ A卡I卡加速支持
|
||||
|
||||
点此查看我们的[演示视频](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
||||
|
||||
## 环境配置
|
||||
以下指令需在 Python 版本大于3.8的环境中执行。
|
||||
|
||||
(Windows/Linux)
|
||||
首先通过 pip 安装主要依赖:
|
||||
### Windows/Linux/MacOS等平台通用方法
|
||||
下列方法任选其一。
|
||||
#### 1. 通过 pip 安装依赖
|
||||
1. 安装Pytorch及其核心依赖,若已安装则跳过。参考自: https://pytorch.org/get-started/locally/
|
||||
```bash
|
||||
# 安装Pytorch及其核心依赖,若已安装则跳过
|
||||
# 参考自: https://pytorch.org/get-started/locally/
|
||||
pip install torch torchvision torchaudio
|
||||
|
||||
#如果是win系统+Nvidia Ampere架构(RTX30xx),根据 #21 的经验,需要指定pytorch对应的cuda版本
|
||||
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
```
|
||||
2. 如果是 win 系统 + Nvidia Ampere 架构(RTX30xx),根据 #21 的经验,需要指定 pytorch 对应的 cuda 版本
|
||||
```bash
|
||||
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
```
|
||||
3. 根据自己的显卡安装对应依赖
|
||||
- N卡
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
- A卡/I卡
|
||||
```bash
|
||||
pip install -r requirements-dml.txt
|
||||
```
|
||||
- A卡ROCM(Linux)
|
||||
```bash
|
||||
pip install -r requirements-amd.txt
|
||||
```
|
||||
- I卡IPEX(Linux)
|
||||
```bash
|
||||
pip install -r requirements-ipex.txt
|
||||
```
|
||||
|
||||
可以使用 poetry 来安装依赖:
|
||||
#### 2. 通过 poetry 来安装依赖
|
||||
安装 Poetry 依赖管理工具,若已安装则跳过。参考自: https://python-poetry.org/docs/#installation
|
||||
```bash
|
||||
# 安装 Poetry 依赖管理工具, 若已安装则跳过
|
||||
# 参考自: https://python-poetry.org/docs/#installation
|
||||
curl -sSL https://install.python-poetry.org | python3 -
|
||||
|
||||
# 通过poetry安装依赖
|
||||
poetry install
|
||||
```
|
||||
|
||||
你也可以通过 pip 来安装依赖:
|
||||
通过 Poetry 安装依赖时,python 建议使用 3.7-3.10 版本,其余版本在安装 llvmlite==0.39.0 时会出现冲突
|
||||
```bash
|
||||
N卡:
|
||||
pip install -r requirements.txt
|
||||
|
||||
A卡/I卡:
|
||||
pip install -r requirements-dml.txt
|
||||
|
||||
A卡Rocm(Linux):
|
||||
pip install -r requirements-amd.txt
|
||||
|
||||
I卡IPEX(Linux):
|
||||
pip install -r requirements-ipex.txt
|
||||
poetry init -n
|
||||
poetry env use "path to your python.exe"
|
||||
poetry run pip install -r requirments.txt
|
||||
```
|
||||
|
||||
------
|
||||
Mac 用户可以通过 `run.sh` 来安装依赖:
|
||||
### MacOS
|
||||
可以通过 `run.sh` 来安装依赖
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
|
|
@ -97,48 +112,48 @@ RVC需要其他一些预模型来推理和训练。
|
|||
|
||||
你可以从我们的[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)下载到这些模型。
|
||||
|
||||
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称:
|
||||
### 1. 下载 assets
|
||||
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称。你可以在`tools`文件夹找到下载它们的脚本。
|
||||
|
||||
- ./assets/hubert/hubert_base.pt
|
||||
|
||||
- ./assets/pretrained
|
||||
|
||||
- ./assets/uvr5_weights
|
||||
|
||||
想使用v2版本模型的话,需要额外下载
|
||||
|
||||
- ./assets/pretrained_v2
|
||||
|
||||
### 2. 安装 ffmpeg
|
||||
若ffmpeg和ffprobe已安装则跳过。
|
||||
|
||||
#### Ubuntu/Debian 用户
|
||||
```bash
|
||||
./assets/hubert/hubert_base.pt
|
||||
|
||||
./assets/pretrained
|
||||
|
||||
./assets/uvr5_weights
|
||||
|
||||
想测试v2版本模型的话,需要额外下载
|
||||
|
||||
./assets/pretrained_v2
|
||||
|
||||
如果你正在使用Windows,则你可能需要这个文件,若ffmpeg和ffprobe已安装则跳过; ubuntu/debian 用户可以通过apt install ffmpeg来安装这2个库, Mac 用户则可以通过brew install ffmpeg来安装 (需要预先安装brew)
|
||||
|
||||
./ffmpeg
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
||||
|
||||
./ffprobe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
||||
|
||||
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于RVC根目录
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||
|
||||
A卡I卡用户需要的dml环境要请下载
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
||||
|
||||
sudo apt install ffmpeg
|
||||
```
|
||||
之后使用以下指令来启动WebUI:
|
||||
#### MacOS 用户
|
||||
```bash
|
||||
python infer-web.py
|
||||
brew install ffmpeg
|
||||
```
|
||||
如果你正在使用Windows 或 macOS,你可以直接下载并解压`RVC-beta.7z`,前者可以运行`go-web.bat`以启动WebUI,后者则运行命令`sh ./run.sh`以启动WebUI。
|
||||
#### Windows 用户
|
||||
下载后放置在根目录。
|
||||
- 下载[ffmpeg.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
|
||||
|
||||
对于需要使用IPEX技术的I卡用户,请先在终端执行`source /opt/intel/oneapi/setvars.sh`(仅Linux)。
|
||||
- 下载[ffprobe.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
|
||||
|
||||
仓库内还有一份`小白简易教程.doc`以供参考。
|
||||
### 3. 下载 rmvpe 人声音高提取算法所需文件
|
||||
|
||||
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于RVC根目录。
|
||||
|
||||
- 下载[rmvpe.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
|
||||
|
||||
#### 下载 rmvpe 的 dml 环境(可选, A卡/I卡用户)
|
||||
|
||||
- 下载[rmvpe.onnx](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
|
||||
|
||||
### 4. AMD显卡Rocm(可选, 仅Linux)
|
||||
|
||||
## AMD显卡Rocm相关(仅Linux)
|
||||
如果你想基于AMD的Rocm技术在Linux系统上运行RVC,请先在[这里](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)安装所需的驱动。
|
||||
|
||||
若你使用的是Arch Linux,可以使用pacman来安装所需驱动:
|
||||
|
|
@ -155,11 +170,32 @@ export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
|||
sudo usermod -aG render $USERNAME
|
||||
sudo usermod -aG video $USERNAME
|
||||
````
|
||||
之后运行WebUI:
|
||||
|
||||
## 开始使用
|
||||
### 直接启动
|
||||
使用以下指令来启动 WebUI
|
||||
```bash
|
||||
python infer-web.py
|
||||
```
|
||||
|
||||
若先前使用 Poetry 安装依赖,则可以通过以下方式启动WebUI
|
||||
```bash
|
||||
poetry run python infer-web.py
|
||||
```
|
||||
|
||||
### 使用整合包
|
||||
下载并解压`RVC-beta.7z`
|
||||
#### Windows 用户
|
||||
双击`go-web.bat`
|
||||
#### MacOS 用户
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
### 对于需要使用IPEX技术的I卡用户(仅Linux)
|
||||
```bash
|
||||
source /opt/intel/oneapi/setvars.sh
|
||||
```
|
||||
|
||||
## 参考项目
|
||||
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
+ [VITS](https://github.com/jaywalnut310/vits)
|
||||
|
|
|
|||
|
|
@ -290,7 +290,7 @@
|
|||
"\n",
|
||||
"!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
|
||||
"\n",
|
||||
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME}"
|
||||
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME} True"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
|
|||
|
|
@ -309,7 +309,7 @@
|
|||
"\n",
|
||||
"!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
|
||||
"\n",
|
||||
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME}"
|
||||
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME} True"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
|
|||
|
|
@ -1 +1 @@
|
|||
{"pth_path": "assets/weights/kikiV1.pth", "index_path": "logs/kikiV1.index", "sg_input_device": "VoiceMeeter Output (VB-Audio Vo (MME)", "sg_output_device": "VoiceMeeter Input (VB-Audio Voi (MME)", "sr_type": "sr_model", "threhold": -60.0, "pitch": 12.0, "rms_mix_rate": 0.5, "index_rate": 0.0, "block_time": 0.2, "crossfade_length": 0.08, "extra_time": 2.00, "n_cpu": 4.0, "use_jit": false, "use_pv": false, "f0method": "fcpe"}
|
||||
{"pth_path": "assets/weights/kikiV1.pth", "index_path": "logs/kikiV1.index", "sg_hostapi": "MME", "sg_wasapi_exclusive": false, "sg_input_device": "VoiceMeeter Output (VB-Audio Vo", "sg_output_device": "VoiceMeeter Input (VB-Audio Voi", "sr_type": "sr_device", "threhold": -60.0, "pitch": 12.0, "rms_mix_rate": 0.5, "index_rate": 0.0, "block_time": 0.15, "crossfade_length": 0.08, "extra_time": 2.0, "n_cpu": 4.0, "use_jit": false, "use_pv": false, "f0method": "fcpe"}
|
||||
|
|
@ -58,6 +58,7 @@ class Config:
|
|||
self.dml,
|
||||
) = self.arg_parse()
|
||||
self.instead = ""
|
||||
self.preprocess_per = 3.7
|
||||
self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
|
||||
|
||||
@staticmethod
|
||||
|
|
@ -127,11 +128,8 @@ class Config:
|
|||
strr = f.read().replace("true", "false")
|
||||
with open(f"configs/{config_file}", "w") as f:
|
||||
f.write(strr)
|
||||
with open("infer/modules/train/preprocess.py", "r") as f:
|
||||
strr = f.read().replace("3.7", "3.0")
|
||||
with open("infer/modules/train/preprocess.py", "w") as f:
|
||||
f.write(strr)
|
||||
print("overwrite preprocess and configs.json")
|
||||
self.preprocess_per = 3.0
|
||||
logger.info("overwrite configs.json")
|
||||
|
||||
def device_config(self) -> tuple:
|
||||
if torch.cuda.is_available():
|
||||
|
|
@ -161,10 +159,7 @@ class Config:
|
|||
+ 0.4
|
||||
)
|
||||
if self.gpu_mem <= 4:
|
||||
with open("infer/modules/train/preprocess.py", "r") as f:
|
||||
strr = f.read().replace("3.7", "3.0")
|
||||
with open("infer/modules/train/preprocess.py", "w") as f:
|
||||
f.write(strr)
|
||||
self.preprocess_per = 3.0
|
||||
elif self.has_mps():
|
||||
logger.info("No supported Nvidia GPU found")
|
||||
self.device = self.instead = "mps"
|
||||
|
|
@ -247,5 +242,8 @@ class Config:
|
|||
)
|
||||
except:
|
||||
pass
|
||||
print("is_half:%s, device:%s" % (self.is_half, self.device))
|
||||
logger.info(
|
||||
"Half-precision floating-point: %s, device: %s"
|
||||
% (self.is_half, self.device)
|
||||
)
|
||||
return x_pad, x_query, x_center, x_max
|
||||
|
|
|
|||
|
|
@ -14,44 +14,52 @@ An easy-to-use Voice Conversion framework based on VITS.<br><br>
|
|||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
</div>
|
||||
|
||||
------
|
||||
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md)
|
||||
|
||||
</div>
|
||||
|
||||
Check our [Demo Video](https://www.bilibili.com/video/BV1pm4y1z7Gm/) here!
|
||||
> Check out our [Demo Video](https://www.bilibili.com/video/BV1pm4y1z7Gm/) here!
|
||||
|
||||
Training/Inference WebUI:go-web.bat
|
||||
<table>
|
||||
<tr>
|
||||
<td align="center">Training and inference Webui</td>
|
||||
<td align="center">Real-time voice changing GUI</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/092e5c12-0d49-4168-a590-0b0ef6a4f630"></td>
|
||||
<td align="center"><img src="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/assets/129054828/730b4114-8805-44a1-ab1a-04668f3c30a6"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">go-web.bat</td>
|
||||
<td align="center">go-realtime-gui.bat</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center">You can freely choose the action you want to perform.</td>
|
||||
<td align="center">We have achieved an end-to-end latency of 170ms. With the use of ASIO input and output devices, we have managed to achieve an end-to-end latency of 90ms, but it is highly dependent on hardware driver support.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
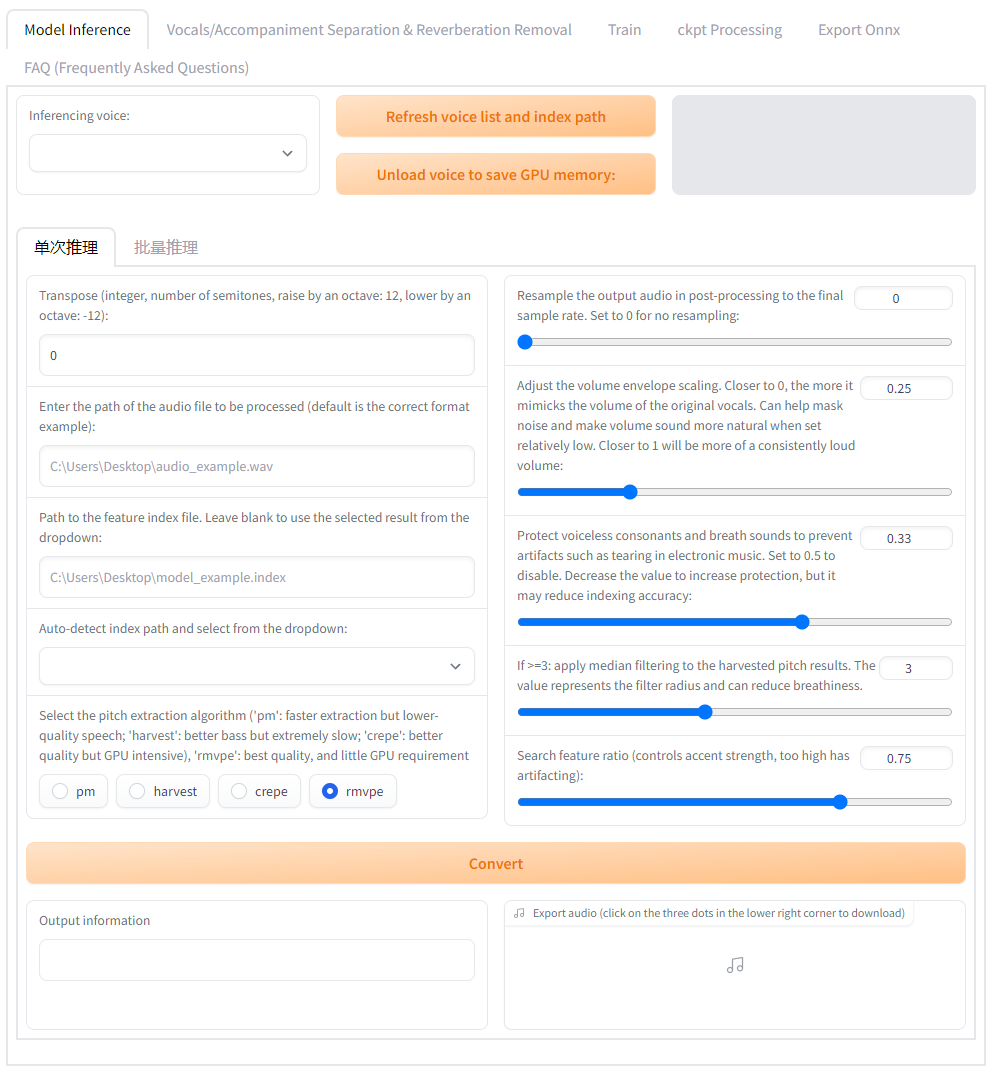
|
||||
> The dataset for the pre-training model uses nearly 50 hours of high quality audio from the VCTK open source dataset.
|
||||
|
||||
Realtime Voice Conversion GUI:go-realtime-gui.bat
|
||||
|
||||

|
||||
|
||||
> The dataset for the pre-training model uses nearly 50 hours of high quality VCTK open source dataset.
|
||||
|
||||
> High quality licensed song datasets will be added to training-set one after another for your use, without worrying about copyright infringement.
|
||||
> High quality licensed song datasets will be added to the training-set often for your use, without having to worry about copyright infringement.
|
||||
|
||||
> Please look forward to the pretrained base model of RVCv3, which has larger parameters, more training data, better results, unchanged inference speed, and requires less training data for training.
|
||||
|
||||
## Summary
|
||||
This repository has the following features:
|
||||
## Features:
|
||||
+ Reduce tone leakage by replacing the source feature to training-set feature using top1 retrieval;
|
||||
+ Easy and fast training, even on relatively poor graphics cards;
|
||||
+ Training with a small amount of data also obtains relatively good results (>=10min low noise speech recommended);
|
||||
+ Supporting model fusion to change timbres (using ckpt processing tab->ckpt merge);
|
||||
+ Easy-to-use Webui interface;
|
||||
+ Use the UVR5 model to quickly separate vocals and instruments.
|
||||
+ Use the most powerful High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent the muted sound problem. Provides the best results (significantly) and is faster, with even lower resource consumption than Crepe_full.
|
||||
+ AMD/Intel graphics cards acceleration supported.
|
||||
+ Easy + fast training, even on poor graphics cards;
|
||||
+ Training with a small amounts of data (>=10min low noise speech recommended);
|
||||
+ Model fusion to change timbres (using ckpt processing tab->ckpt merge);
|
||||
+ Easy-to-use WebUI;
|
||||
+ UVR5 model to quickly separate vocals and instruments;
|
||||
+ High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent a muted sound problem. Provides the best results (significantly) and is faster with lower resource consumption than Crepe_full;
|
||||
+ AMD/Intel graphics cards acceleration supported;
|
||||
+ Intel ARC graphics cards acceleration with IPEX supported.
|
||||
|
||||
## Preparing the environment
|
||||
The following commands need to be executed in the environment of Python version 3.8 or higher.
|
||||
The following commands need to be executed with Python 3.8 or higher.
|
||||
|
||||
(Windows/Linux)
|
||||
First install the main dependencies through pip:
|
||||
|
|
@ -125,15 +133,6 @@ If you want to test the v2 version model (the v2 version model has changed the i
|
|||
|
||||
./assets/pretrained_v2
|
||||
|
||||
#If you are using Windows, you may also need these two files, skip if FFmpeg and FFprobe are installed
|
||||
ffmpeg.exe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
||||
|
||||
ffprobe.exe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
||||
|
||||
If you want to use the latest SOTA RMVPE vocal pitch extraction algorithm, you need to download the RMVPE weights and place them in the RVC root directory
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||
|
|
@ -144,14 +143,22 @@ https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
|||
|
||||
```
|
||||
|
||||
Intel ARC graphics cards users needs to run `source /opt/intel/oneapi/setvars.sh` command before starting Webui.
|
||||
### 2. Install FFmpeg
|
||||
If you have FFmpeg and FFprobe installed on your computer, you can skip this step.
|
||||
|
||||
Then use this command to start Webui:
|
||||
#### For Ubuntu/Debian users
|
||||
```bash
|
||||
python infer-web.py
|
||||
sudo apt install ffmpeg
|
||||
```
|
||||
#### For MacOS users
|
||||
```bash
|
||||
brew install ffmpeg
|
||||
```
|
||||
#### For Windwos users
|
||||
Download these files and place them in the root folder:
|
||||
- [ffmpeg.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
|
||||
|
||||
If you are using Windows or macOS, you can download and extract `RVC-beta.7z` to use RVC directly by using `go-web.bat` on windows or `sh ./run.sh` on macOS to start Webui.
|
||||
- [ffprobe.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
|
||||
|
||||
## ROCm Support for AMD graphic cards (Linux only)
|
||||
To use ROCm on Linux install all required drivers as described [here](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
|
||||
|
|
@ -166,16 +173,30 @@ You might also need to set these environment variables (e.g. on a RX6700XT):
|
|||
export ROCM_PATH=/opt/rocm
|
||||
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||
````
|
||||
Also make sure your user is part of the `render` and `video` group:
|
||||
Make sure your user is part of the `render` and `video` group:
|
||||
````
|
||||
sudo usermod -aG render $USERNAME
|
||||
sudo usermod -aG video $USERNAME
|
||||
````
|
||||
After that you can run the WebUI:
|
||||
|
||||
## Get started
|
||||
### start up directly
|
||||
Use the following command to start WebUI:
|
||||
```bash
|
||||
python infer-web.py
|
||||
```
|
||||
|
||||
### Use the integration package
|
||||
Download and extract file `RVC-beta.7z`, then follow the steps below according to your system:
|
||||
#### For Windows users
|
||||
双击`go-web.bat`
|
||||
#### For MacOS users
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
### For Intel IPEX users (Linux Only)
|
||||
```bash
|
||||
source /opt/intel/oneapi/setvars.sh
|
||||
```
|
||||
## Credits
|
||||
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
+ [VITS](https://github.com/jaywalnut310/vits)
|
||||
|
|
|
|||
|
|
@ -14,13 +14,13 @@ Un framework simple et facile à utiliser pour la conversion vocale (modificateu
|
|||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
[**Journal de mise à jour**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**FAQ**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
||||
[**Journal de mise à jour**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**FAQ**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·Formation d'un chanteur AI pour 5 centimes**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**Enregistrement des expériences comparatives**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95) | [**Démonstration en ligne**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
||||
|
||||
</div>
|
||||
|
||||
------
|
||||
|
||||
[**English**](./docs/en/README.en.md) |[ **中文简体**](./docs/cn/README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Turc**](./docs/tr/README.tr.md)
|
||||
[**English**](../en/README.en.md) | [ **中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Turc**](../tr/README.tr.md)
|
||||
|
||||
Cliquez ici pour voir notre [vidéo de démonstration](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
||||
|
||||
|
|
@ -39,10 +39,10 @@ Ce dépôt a les caractéristiques suivantes :
|
|||
+ Interface web simple et facile à utiliser.
|
||||
+ Peut appeler le modèle UVR5 pour séparer rapidement la voix et l'accompagnement.
|
||||
+ Utilise l'algorithme de pitch vocal le plus avancé [InterSpeech2023-RMVPE](#projets-référencés) pour éliminer les problèmes de voix muette. Meilleurs résultats, plus rapide que crepe_full, et moins gourmand en ressources.
|
||||
+ Support d'accélération pour les cartes A et I.
|
||||
+ Support d'accélération pour les cartes AMD et Intel.
|
||||
|
||||
## Configuration de l'environnement
|
||||
Exécutez les commandes suivantes dans un environnement Python de version supérieure à 3.8.
|
||||
Exécutez les commandes suivantes dans un environnement Python de version 3.8 ou supérieure.
|
||||
|
||||
(Windows/Linux)
|
||||
Installez d'abord les dépendances principales via pip :
|
||||
|
|
@ -52,7 +52,10 @@ Installez d'abord les dépendances principales via pip :
|
|||
pip install torch torchvision torchaudio
|
||||
|
||||
# Pour les utilisateurs de Windows avec une architecture Nvidia Ampere (RTX30xx), en se basant sur l'expérience #21, spécifiez la version CUDA correspondante pour Pytorch.
|
||||
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
|
||||
# Pour Linux + carte AMD, utilisez cette version de Pytorch:
|
||||
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
|
||||
```
|
||||
|
||||
Vous pouvez utiliser poetry pour installer les dépendances :
|
||||
|
|
@ -67,15 +70,17 @@ poetry install
|
|||
|
||||
Ou vous pouvez utiliser pip pour installer les dépendances :
|
||||
```bash
|
||||
Cartes Nvidia :
|
||||
|
||||
# Cartes Nvidia :
|
||||
pip install -r requirements.txt
|
||||
|
||||
Cartes AMD/Intel :
|
||||
pip install -
|
||||
# Cartes AMD/Intel :
|
||||
pip install -r requirements-dml.txt
|
||||
|
||||
r requirements-dml.txt
|
||||
# Cartes Intel avec IPEX
|
||||
pip install -r requirements-ipex.txt
|
||||
|
||||
# Cartes AMD sur Linux (ROCm)
|
||||
pip install -r requirements-amd.txt
|
||||
```
|
||||
|
||||
------
|
||||
|
|
@ -87,7 +92,12 @@ sh ./run.sh
|
|||
## Préparation d'autres modèles pré-entraînés
|
||||
RVC nécessite d'autres modèles pré-entraînés pour l'inférence et la formation.
|
||||
|
||||
Vous pouvez télécharger ces modèles depuis notre [espace Hugging Face](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
|
||||
```bash
|
||||
#Télécharger tous les modèles depuis https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/
|
||||
python tools/download_models.py
|
||||
```
|
||||
|
||||
Ou vous pouvez télécharger ces modèles depuis notre [espace Hugging Face](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
|
||||
|
||||
Voici une liste des modèles et autres fichiers requis par RVC :
|
||||
```bash
|
||||
|
|
@ -97,29 +107,30 @@ Voici une liste des modèles et autres fichiers requis par RVC :
|
|||
|
||||
./assets/uvr5_weights
|
||||
|
||||
Pour tester la version v2 du modèle, téléchargez également :
|
||||
# Pour tester la version v2 du modèle, téléchargez également :
|
||||
|
||||
./assets/pretrained_v2
|
||||
|
||||
Si vous utilisez Windows, vous pourriez avoir besoin de ces fichiers pour ffmpeg et ffprobe, sautez cette étape si vous avez déjà installé ffmpeg et ffprobe. Les utilisateurs d'ubuntu/debian peuvent installer ces deux bibliothèques avec apt install ffmpeg. Les utilisateurs de Mac peuvent les installer avec brew install ffmpeg (prérequis : avoir installé brew).
|
||||
# Si vous utilisez Windows, vous pourriez avoir besoin de ces fichiers pour ffmpeg et ffprobe, sautez cette étape si vous avez déjà installé ffmpeg et ffprobe. Les utilisateurs d'ubuntu/debian peuvent installer ces deux bibliothèques avec apt install ffmpeg. Les utilisateurs de Mac peuvent les installer avec brew install ffmpeg (prérequis : avoir installé brew).
|
||||
|
||||
./ffmpeg
|
||||
# ./ffmpeg
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
||||
|
||||
./ffprobe
|
||||
# ./ffprobe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
||||
|
||||
Si vous souhaitez utiliser le dernier algorithme RMVPE de pitch vocal, téléchargez les paramètres du modèle de pitch et placez-les dans le répertoire racine de RVC.
|
||||
# Si vous souhaitez utiliser le dernier algorithme RMVPE de pitch vocal, téléchargez les paramètres du modèle de pitch et placez-les dans le répertoire racine de RVC.
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||
|
||||
Les utilisateurs de cartes AMD/Intel nécessitant l'environnement DML doivent télécharger :
|
||||
# Les utilisateurs de cartes AMD/Intel nécessitant l'environnement DML doivent télécharger :
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
||||
|
||||
```
|
||||
Pour les utilisateurs d'Intel ARC avec IPEX, exécutez d'abord `source /opt/intel/oneapi/setvars.sh`.
|
||||
Ensuite, exécutez la commande suivante pour démarrer WebUI :
|
||||
```bash
|
||||
python infer-web.py
|
||||
|
|
@ -127,7 +138,28 @@ python infer-web.py
|
|||
|
||||
Si vous utilisez Windows ou macOS, vous pouvez télécharger et extraire `RVC-beta.7z`. Les utilisateurs de Windows peuvent exécuter `go-web.bat` pour démarrer WebUI, tandis que les utilisateurs de macOS peuvent exécuter `sh ./run.sh`.
|
||||
|
||||
Il y a également un `Guide facile pour les débutants.doc` inclus pour référence.
|
||||
## Compatibilité ROCm pour les cartes AMD (seulement Linux)
|
||||
Installez tous les pilotes décrits [ici](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
|
||||
|
||||
Sur Arch utilisez pacman pour installer le pilote:
|
||||
````
|
||||
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
||||
````
|
||||
|
||||
Vous devrez peut-être créer ces variables d'environnement (par exemple avec RX6700XT):
|
||||
````
|
||||
export ROCM_PATH=/opt/rocm
|
||||
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||
````
|
||||
Assurez-vous que votre utilisateur est dans les groupes `render` et `video`:
|
||||
````
|
||||
sudo usermod -aG render $USERNAME
|
||||
sudo usermod -aG video $USERNAME
|
||||
````
|
||||
Enfin vous pouvez exécuter WebUI:
|
||||
```bash
|
||||
python infer-web.py
|
||||
```
|
||||
|
||||
## Crédits
|
||||
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ VITSに基づく使いやすい音声変換(voice changer)framework<br><br>
|
|||
|
||||
[**更新日誌**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md)
|
||||
|
||||
> デモ動画は[こちら](https://www.bilibili.com/video/BV1pm4y1z7Gm/)でご覧ください。
|
||||
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ VITS基盤의 簡單하고使用하기 쉬운音聲變換틀<br><br>
|
|||
------
|
||||
[**更新日誌**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_KO.md)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md)
|
||||
|
||||
> [示範映像](https://www.bilibili.com/video/BV1pm4y1z7Gm/)을 確認해 보세요!
|
||||
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ VITS 기반의 간단하고 사용하기 쉬운 음성 변환 프레임워크.<b
|
|||
|
||||
[**업데이트 로그**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_KO.md)
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md)
|
||||
|
||||
> [데모 영상](https://www.bilibili.com/video/BV1pm4y1z7Gm/)을 확인해 보세요!
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,105 @@
|
|||
### 2023-10-06
|
||||
- Criamos uma GUI para alteração de voz em tempo real: go-realtime-gui.bat/gui_v1.py (observe que você deve escolher o mesmo tipo de dispositivo de entrada e saída, por exemplo, MME e MME).
|
||||
- Treinamos um modelo RMVPE de extração de pitch melhor.
|
||||
- Otimizar o layout da GUI de inferência.
|
||||
|
||||
### 2023-08-13
|
||||
1-Correção de bug regular
|
||||
- Alterar o número total mínimo de épocas para 1 e alterar o número total mínimo de epoch para 2
|
||||
- Correção de erros de treinamento por não usar modelos de pré-treinamento
|
||||
- Após a separação dos vocais de acompanhamento, limpe a memória dos gráficos
|
||||
- Alterar o caminho absoluto do faiss save para o caminho relativo
|
||||
- Suporte a caminhos com espaços (tanto o caminho do conjunto de treinamento quanto o nome do experimento são suportados, e os erros não serão mais relatados)
|
||||
- A lista de arquivos cancela a codificação utf8 obrigatória
|
||||
- Resolver o problema de consumo de CPU causado pela busca do faiss durante alterações de voz em tempo real
|
||||
|
||||
Atualizações do 2-Key
|
||||
- Treine o modelo de extração de pitch vocal de código aberto mais forte do momento, o RMVPE, e use-o para treinamento de RVC, inferência off-line/em tempo real, com suporte a PyTorch/Onnx/DirectML
|
||||
- Suporte para placas gráficas AMD e Intel por meio do Pytorch_DML
|
||||
|
||||
(1) Mudança de voz em tempo real (2) Inferência (3) Separação do acompanhamento vocal (4) Não há suporte para treinamento no momento, mudaremos para treinamento de CPU; há suporte para inferência RMVPE de gpu por Onnx_Dml
|
||||
|
||||
|
||||
### 2023-06-18
|
||||
- Novos modelos v2 pré-treinados: 32k e 48k
|
||||
- Correção de erros de inferência de modelo não-f0
|
||||
- Para conjuntos de treinamento que excedam 1 hora, faça minibatch-kmeans automáticos para reduzir a forma dos recursos, de modo que o treinamento, a adição e a pesquisa do Index sejam muito mais rápidos.
|
||||
- Fornecer um espaço de brinquedo vocal2guitar huggingface
|
||||
- Exclusão automática de áudios de conjunto de treinamento de atalhos discrepantes
|
||||
- Guia de exportação Onnx
|
||||
|
||||
Experimentos com falha:
|
||||
- ~~Recuperação de recurso: adicionar recuperação de recurso temporal: não eficaz~~
|
||||
- ~~Recuperação de recursos: adicionar redução de dimensionalidade PCAR: a busca é ainda mais lenta~~
|
||||
- ~~Aumento de dados aleatórios durante o treinamento: não é eficaz~~
|
||||
|
||||
Lista de tarefas:
|
||||
- ~~Vocos-RVC (vocoder minúsculo): não é eficaz~~
|
||||
- ~~Suporte de crepe para treinamento: substituído pelo RMVPE~~
|
||||
- ~~Inferência de crepe de meia precisão:substituída pelo RMVPE. E difícil de conseguir.~~
|
||||
- Suporte ao editor de F0
|
||||
|
||||
### 2023-05-28
|
||||
- Adicionar notebook jupyter v2, changelog em coreano, corrigir alguns requisitos de ambiente
|
||||
- Adicionar consoante sem voz e modo de proteção de respiração
|
||||
- Suporte à detecção de pitch crepe-full
|
||||
- Separação vocal UVR5: suporte a modelos dereverb e modelos de-echo
|
||||
- Adicionar nome e versão do experimento no nome do Index
|
||||
- Suporte aos usuários para selecionar manualmente o formato de exportação dos áudios de saída durante o processamento de conversão de voz em lote e a separação vocal UVR5
|
||||
- Não há mais suporte para o treinamento do modelo v1 32k
|
||||
|
||||
### 2023-05-13
|
||||
- Limpar os códigos redundantes na versão antiga do tempo de execução no pacote de um clique: lib.infer_pack e uvr5_pack
|
||||
- Correção do bug de pseudo multiprocessamento no pré-processamento do conjunto de treinamento
|
||||
- Adição do ajuste do raio de filtragem mediana para o algoritmo de reconhecimento de inclinação da extração
|
||||
- Suporte à reamostragem de pós-processamento para exportação de áudio
|
||||
- A configuração "n_cpu" de multiprocessamento para treinamento foi alterada de "extração de f0" para "pré-processamento de dados e extração de f0"
|
||||
- Detectar automaticamente os caminhos de Index na pasta de registros e fornecer uma função de lista suspensa
|
||||
- Adicionar "Perguntas e respostas frequentes" na página da guia (você também pode consultar o wiki do RVC no github)
|
||||
- Durante a inferência, o pitch da colheita é armazenado em cache quando se usa o mesmo caminho de áudio de entrada (finalidade: usando a extração do pitch da colheita, todo o pipeline passará por um processo longo e repetitivo de extração do pitch. Se o armazenamento em cache não for usado, os usuários que experimentarem diferentes configurações de raio de filtragem de timbre, Index e mediana de pitch terão um processo de espera muito doloroso após a primeira inferência)
|
||||
|
||||
### 2023-05-14
|
||||
- Use o envelope de volume da entrada para misturar ou substituir o envelope de volume da saída (pode aliviar o problema de "muting de entrada e ruído de pequena amplitude de saída"). Se o ruído de fundo do áudio de entrada for alto, não é recomendável ativá-lo, e ele não é ativado por padrão (1 pode ser considerado como não ativado)
|
||||
- Suporte ao salvamento de modelos pequenos extraídos em uma frequência especificada (se você quiser ver o desempenho em épocas diferentes, mas não quiser salvar todos os pontos de verificação grandes e extrair manualmente modelos pequenos pelo processamento ckpt todas as vezes, esse recurso será muito prático)
|
||||
- Resolver o problema de "erros de conexão" causados pelo proxy global do servidor, definindo variáveis de ambiente
|
||||
- Oferece suporte a modelos v2 pré-treinados (atualmente, apenas as versões 40k estão disponíveis publicamente para teste e as outras duas taxas de amostragem ainda não foram totalmente treinadas)
|
||||
- Limita o volume excessivo que excede 1 antes da inferência
|
||||
- Ajustou ligeiramente as configurações do pré-processamento do conjunto de treinamento
|
||||
|
||||
|
||||
#######################
|
||||
|
||||
Histórico de registros de alterações:
|
||||
|
||||
### 2023-04-09
|
||||
- Parâmetros de treinamento corrigidos para melhorar a taxa de utilização da GPU: A100 aumentou de 25% para cerca de 90%, V100: 50% para cerca de 90%, 2060S: 60% para cerca de 85%, P40: 25% para cerca de 95%; melhorou significativamente a velocidade de treinamento
|
||||
- Parâmetro alterado: total batch_size agora é por GPU batch_size
|
||||
- Total_epoch alterado: limite máximo aumentado de 100 para 1000; padrão aumentado de 10 para 20
|
||||
- Corrigido o problema da extração de ckpt que reconhecia o pitch incorretamente, causando inferência anormal
|
||||
- Corrigido o problema do treinamento distribuído que salvava o ckpt para cada classificação
|
||||
- Aplicada a filtragem de recursos nan para extração de recursos
|
||||
- Corrigido o problema com a entrada/saída silenciosa que produzia consoantes aleatórias ou ruído (os modelos antigos precisavam ser treinados novamente com um novo conjunto de dados)
|
||||
|
||||
### Atualização 2023-04-16
|
||||
- Adicionada uma mini-GUI de alteração de voz local em tempo real, iniciada com um clique duplo em go-realtime-gui.bat
|
||||
- Filtragem aplicada para bandas de frequência abaixo de 50 Hz durante o treinamento e a inferência
|
||||
- Diminuição da extração mínima de tom do pyworld do padrão 80 para 50 para treinamento e inferência, permitindo que vozes masculinas de tom baixo entre 50-80 Hz não sejam silenciadas
|
||||
- A WebUI suporta a alteração de idiomas de acordo com a localidade do sistema (atualmente suporta en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW; o padrão é en_US se não for suportado)
|
||||
- Correção do reconhecimento de algumas GPUs (por exemplo, falha no reconhecimento da V100-16G, falha no reconhecimento da P4)
|
||||
|
||||
### Atualização de 2023-04-28
|
||||
- Atualizadas as configurações do Index faiss para maior velocidade e qualidade
|
||||
- Removida a dependência do total_npy; o futuro compartilhamento de modelos não exigirá a entrada do total_npy
|
||||
- Restrições desbloqueadas para as GPUs da série 16, fornecendo configurações de inferência de 4 GB para GPUs com VRAM de 4 GB
|
||||
- Corrigido o erro na separação do acompanhamento vocal do UVR5 para determinados formatos de áudio
|
||||
- A mini-GUI de alteração de voz em tempo real agora suporta modelos de pitch não 40k e que não são lentos
|
||||
|
||||
### Planos futuros:
|
||||
Recursos:
|
||||
- Opção de adição: extrair modelos pequenos para cada epoch salvo
|
||||
- Adicionar opção: exportar mp3 adicional para o caminho especificado durante a inferência
|
||||
- Suporte à guia de treinamento para várias pessoas (até 4 pessoas)
|
||||
|
||||
Modelo básico:
|
||||
- Coletar arquivos wav de respiração para adicionar ao conjunto de dados de treinamento para corrigir o problema de sons de respiração distorcidos
|
||||
- No momento, estamos treinando um modelo básico com um conjunto de dados de canto estendido, que será lançado no futuro
|
||||
|
|
@ -0,0 +1,193 @@
|
|||
<div align="center">
|
||||
|
||||
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
||||
Uma estrutura de conversão de voz fácil de usar baseada em VITS.<br><br>
|
||||
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
||||
|
||||
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
||||
|
||||
[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
||||
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
||||
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
||||
|
||||
[](https://discord.gg/HcsmBBGyVk)
|
||||
|
||||
</div>
|
||||
|
||||
------
|
||||
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
||||
|
||||
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
|
||||
|
||||
Confira nosso [Vídeo de demonstração](https://www.bilibili.com/video/BV1pm4y1z7Gm/) aqui!
|
||||
|
||||
Treinamento/Inferência WebUI:go-web.bat
|
||||

|
||||
|
||||
GUI de conversão de voz em tempo real:go-realtime-gui.bat
|
||||

|
||||
|
||||
|
||||
> O dataset para o modelo de pré-treinamento usa quase 50 horas de conjunto de dados de código aberto VCTK de alta qualidade.
|
||||
|
||||
> Dataset de músicas licenciadas de alta qualidade serão adicionados ao conjunto de treinamento, um após o outro, para seu uso, sem se preocupar com violação de direitos autorais.
|
||||
|
||||
> Aguarde o modelo básico pré-treinado do RVCv3, que possui parâmetros maiores, mais dados de treinamento, melhores resultados, velocidade de inferência inalterada e requer menos dados de treinamento para treinamento.
|
||||
|
||||
## Resumo
|
||||
Este repositório possui os seguintes recursos:
|
||||
+ Reduza o vazamento de tom substituindo o recurso de origem pelo recurso de conjunto de treinamento usando a recuperação top1;
|
||||
+ Treinamento fácil e rápido, mesmo em placas gráficas relativamente ruins;
|
||||
+ Treinar com uma pequena quantidade de dados também obtém resultados relativamente bons (>=10min de áudio com baixo ruído recomendado);
|
||||
+ Suporta fusão de modelos para alterar timbres (usando guia de processamento ckpt-> mesclagem ckpt);
|
||||
+ Interface Webui fácil de usar;
|
||||
+ Use o modelo UVR5 para separar rapidamente vocais e instrumentos.
|
||||
+ Use o mais poderoso algoritmo de extração de voz de alta frequência [InterSpeech2023-RMVPE](#Credits) para evitar o problema de som mudo. Fornece os melhores resultados (significativamente) e é mais rápido, com consumo de recursos ainda menor que o Crepe_full.
|
||||
+ Suporta aceleração de placas gráficas AMD/Intel.
|
||||
+ Aceleração de placas gráficas Intel ARC com suporte para IPEX.
|
||||
|
||||
## Preparando o ambiente
|
||||
Os comandos a seguir precisam ser executados no ambiente Python versão 3.8 ou superior.
|
||||
|
||||
(Windows/Linux)
|
||||
Primeiro instale as dependências principais através do pip:
|
||||
```bash
|
||||
# Instale as dependências principais relacionadas ao PyTorch, pule se instaladas
|
||||
# Referência: https://pytorch.org/get-started/locally/
|
||||
pip install torch torchvision torchaudio
|
||||
|
||||
#Para arquitetura Windows + Nvidia Ampere (RTX30xx), você precisa especificar a versão cuda correspondente ao pytorch de acordo com a experiência de https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/issues/ 21
|
||||
#pip instalar tocha torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
||||
|
||||
#Para placas Linux + AMD, você precisa usar as seguintes versões do pytorch:
|
||||
#pip instalar tocha torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
|
||||
```
|
||||
|
||||
Então pode usar poesia para instalar as outras dependências:
|
||||
```bash
|
||||
# Instale a ferramenta de gerenciamento de dependências Poetry, pule se instalada
|
||||
# Referência: https://python-poetry.org/docs/#installation
|
||||
curl -sSL https://install.python-poetry.org | python3 -
|
||||
|
||||
#Instale as dependências do projeto
|
||||
poetry install
|
||||
```
|
||||
|
||||
Você também pode usar pip para instalá-los:
|
||||
```bash
|
||||
|
||||
for Nvidia graphics cards
|
||||
pip install -r requirements.txt
|
||||
|
||||
for AMD/Intel graphics cards on Windows (DirectML):
|
||||
pip install -r requirements-dml.txt
|
||||
|
||||
for Intel ARC graphics cards on Linux / WSL using Python 3.10:
|
||||
pip install -r requirements-ipex.txt
|
||||
|
||||
for AMD graphics cards on Linux (ROCm):
|
||||
pip install -r requirements-amd.txt
|
||||
```
|
||||
|
||||
------
|
||||
Usuários de Mac podem instalar dependências via `run.sh`:
|
||||
```bash
|
||||
sh ./run.sh
|
||||
```
|
||||
|
||||
## Preparação de outros Pré-modelos
|
||||
RVC requer outros pré-modelos para inferir e treinar.
|
||||
|
||||
```bash
|
||||
#Baixe todos os modelos necessários em https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/
|
||||
python tools/download_models.py
|
||||
```
|
||||
|
||||
Ou apenas baixe-os você mesmo em nosso [Huggingface space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
|
||||
|
||||
Aqui está uma lista de pré-modelos e outros arquivos que o RVC precisa:
|
||||
```bash
|
||||
./assets/hubert/hubert_base.pt
|
||||
|
||||
./assets/pretrained
|
||||
|
||||
./assets/uvr5_weights
|
||||
|
||||
Downloads adicionais são necessários se você quiser testar a versão v2 do modelo.
|
||||
|
||||
./assets/pretrained_v2
|
||||
|
||||
Se você deseja testar o modelo da versão v2 (o modelo da versão v2 alterou a entrada do recurso dimensional 256 do Hubert + final_proj de 9 camadas para o recurso dimensional 768 do Hubert de 12 camadas e adicionou 3 discriminadores de período), você precisará baixar recursos adicionais
|
||||
|
||||
./assets/pretrained_v2
|
||||
|
||||
#Se você estiver usando Windows, também pode precisar desses dois arquivos, pule se FFmpeg e FFprobe estiverem instalados
|
||||
ffmpeg.exe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
||||
|
||||
ffprobe.exe
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
||||
|
||||
Se quiser usar o algoritmo de extração de tom vocal SOTA RMVPE mais recente, você precisa baixar os pesos RMVPE e colocá-los no diretório raiz RVC
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
||||
|
||||
Para usuários de placas gráficas AMD/Intel, você precisa baixar:
|
||||
|
||||
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
||||
|
||||
```
|
||||
|
||||
Os usuários de placas gráficas Intel ARC precisam executar o comando `source /opt/intel/oneapi/setvars.sh` antes de iniciar o Webui.
|
||||
|
||||
Em seguida, use este comando para iniciar o Webui:
|
||||
```bash
|
||||
python infer-web.py
|
||||
```
|
||||
|
||||
Se estiver usando Windows ou macOS, você pode baixar e extrair `RVC-beta.7z` para usar RVC diretamente usando `go-web.bat` no Windows ou `sh ./run.sh` no macOS para iniciar o Webui.
|
||||
|
||||
## Suporte ROCm para placas gráficas AMD (somente Linux)
|
||||
Para usar o ROCm no Linux, instale todos os drivers necessários conforme descrito [aqui](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
|
||||
|
||||
No Arch use pacman para instalar o driver:
|
||||
````
|
||||
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
||||
````
|
||||
|
||||
Talvez você também precise definir estas variáveis de ambiente (por exemplo, em um RX6700XT):
|
||||
````
|
||||
export ROCM_PATH=/opt/rocm
|
||||
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
||||
````
|
||||
Verifique também se seu usuário faz parte do grupo `render` e `video`:
|
||||
````
|
||||
sudo usermod -aG render $USERNAME
|
||||
sudo usermod -aG video $USERNAME
|
||||
````
|
||||
Depois disso, você pode executar o WebUI:
|
||||
```bash
|
||||
python infer-web.py
|
||||
```
|
||||
|
||||
## Credits
|
||||
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
||||
+ [VITS](https://github.com/jaywalnut310/vits)
|
||||
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
||||
+ [Gradio](https://github.com/gradio-app/gradio)
|
||||
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
||||
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
||||
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
||||
+ [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
|
||||
+ The pretrained model is trained and tested by [yxlllc](https://github.com/yxlllc/RMVPE) and [RVC-Boss](https://github.com/RVC-Boss).
|
||||
|
||||
## Thanks to all contributors for their efforts
|
||||
<a href="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
||||
<img src="https://contrib.rocks/image?repo=RVC-Project/Retrieval-based-Voice-Conversion-WebUI" />
|
||||
</a>
|
||||
|
||||
|
|
@ -0,0 +1,102 @@
|
|||
pONTAS de afinação FAISS
|
||||
==================
|
||||
# sobre faiss
|
||||
faiss é uma biblioteca de pesquisas de vetores densos na área, desenvolvida pela pesquisa do facebook, que implementa com eficiência muitos métodos de pesquisa de área aproximada.
|
||||
A Pesquisa Aproximada de área encontra vetores semelhantes rapidamente, sacrificando alguma precisão.
|
||||
|
||||
## faiss em RVC
|
||||
No RVC, para a incorporação de recursos convertidos pelo HuBERT, buscamos incorporações semelhantes à incorporação gerada a partir dos dados de treinamento e as misturamos para obter uma conversão mais próxima do discurso original. No entanto, como essa pesquisa leva tempo se realizada de forma ingênua, a conversão de alta velocidade é realizada usando a pesquisa aproximada de área.
|
||||
|
||||
# visão geral da implementação
|
||||
Em '/logs/nome-do-seu-modelo/3_feature256', onde o modelo está localizado, os recursos extraídos pelo HuBERT de cada dado de voz estão localizados.
|
||||
A partir daqui, lemos os arquivos npy ordenados por nome de arquivo e concatenamos os vetores para criar big_npy. (Este vetor tem a forma [N, 256].)
|
||||
Depois de salvar big_npy as /logs/nome-do-seu-modelo/total_fea.npy, treine-o com faiss.
|
||||
|
||||
Neste artigo, explicarei o significado desses parâmetros.
|
||||
|
||||
# Explicação do método
|
||||
## Fábrica de Index
|
||||
Uma fábrica de Index é uma notação faiss exclusiva que expressa um pipeline que conecta vários métodos de pesquisa de área aproximados como uma string.
|
||||
Isso permite que você experimente vários métodos aproximados de pesquisa de área simplesmente alterando a cadeia de caracteres de fábrica do Index.
|
||||
No RVC é usado assim:
|
||||
|
||||
```python
|
||||
index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
|
||||
```
|
||||
Entre os argumentos de index_factory, o primeiro é o número de dimensões do vetor, o segundo é a string de fábrica do Index e o terceiro é a distância a ser usada.
|
||||
|
||||
Para uma notação mais detalhada
|
||||
https://github.com/facebookresearch/faiss/wiki/The-index-factory
|
||||
|
||||
## Construção de Index
|
||||
Existem dois Indexs típicos usados como similaridade de incorporação da seguinte forma.
|
||||
|
||||
- Distância euclidiana (MÉTRICA_L2)
|
||||
- Produto interno (METRIC_INNER_PRODUCT)
|
||||
|
||||
A distância euclidiana toma a diferença quadrática em cada dimensão, soma as diferenças em todas as dimensões e, em seguida, toma a raiz quadrada. Isso é o mesmo que a distância em 2D e 3D que usamos diariamente.
|
||||
O produto interno não é usado como um Index de similaridade como é, e a similaridade de cosseno que leva o produto interno depois de ser normalizado pela norma L2 é geralmente usada.
|
||||
|
||||
O que é melhor depende do caso, mas a similaridade de cosseno é frequentemente usada na incorporação obtida pelo word2vec e modelos de recuperação de imagem semelhantes aprendidos pelo ArcFace. Se você quiser fazer a normalização l2 no vetor X com numpy, você pode fazê-lo com o seguinte código com eps pequeno o suficiente para evitar a divisão 0.
|
||||
|
||||
```python
|
||||
X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
|
||||
```
|
||||
|
||||
Além disso, para a Construção de Index, você pode alterar o Index de distância usado para cálculo escolhendo o valor a ser passado como o terceiro argumento.
|
||||
|
||||
```python
|
||||
index = faiss.index_factory(dimention, text, faiss.METRIC_INNER_PRODUCT)
|
||||
```
|
||||
|
||||
## FI
|
||||
IVF (Inverted file indexes) é um algoritmo semelhante ao Index invertido na pesquisa de texto completo.
|
||||
Durante o aprendizado, o destino da pesquisa é agrupado com kmeans e o particionamento Voronoi é realizado usando o centro de cluster. A cada ponto de dados é atribuído um cluster, por isso criamos um dicionário que procura os pontos de dados dos clusters.
|
||||
|
||||
Por exemplo, se os clusters forem atribuídos da seguinte forma
|
||||
|index|Cluster|
|
||||
|-----|-------|
|
||||
|1|A|
|
||||
|2|B|
|
||||
|3|A|
|
||||
|4|C|
|
||||
|5|B|
|
||||
|
||||
O Index invertido resultante se parece com isso:
|
||||
|
||||
| cluster | Index |
|
||||
|-------|-----|
|
||||
| A | 1, 3 |
|
||||
| B | 2 5 |
|
||||
| C | 4 |
|
||||
|
||||
Ao pesquisar, primeiro pesquisamos n_probe clusters dos clusters e, em seguida, calculamos as distâncias para os pontos de dados pertencentes a cada cluster.
|
||||
|
||||
# Parâmetro de recomendação
|
||||
Existem diretrizes oficiais sobre como escolher um Index, então vou explicar de
|
||||
acordo. https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
|
||||
|
||||
Para conjuntos de dados abaixo de 1M, o 4bit-PQ é o método mais eficiente disponível no faiss em abril de 2023.
|
||||
Combinando isso com a fertilização in vitro, estreitando os candidatos com 4bit-PQ e, finalmente, recalcular a distância com um Index preciso pode ser descrito usando a seguinte fábrica de Indexs.
|
||||
|
||||
```python
|
||||
index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
|
||||
```
|
||||
|
||||
## Parâmetros recomendados para FIV
|
||||
Considere o caso de muitas FIVs. Por exemplo, se a quantização grosseira por FIV for realizada para o número de dados, isso é o mesmo que uma pesquisa exaustiva ingênua e é ineficiente.
|
||||
Para 1M ou menos, os valores de FIV são recomendados entre 4*sqrt(N) ~ 16*sqrt(N) para N número de pontos de dados.
|
||||
|
||||
Como o tempo de cálculo aumenta proporcionalmente ao número de n_sondas, consulte a precisão e escolha adequadamente. Pessoalmente, não acho que o RVC precise de tanta precisão, então n_probe = 1 está bem.
|
||||
|
||||
## FastScan
|
||||
O FastScan é um método que permite a aproximação de alta velocidade de distâncias por quantização de produto cartesiano, realizando-as em registros.
|
||||
A quantização cartesiana do produto executa o agrupamento independentemente para cada dimensão d (geralmente d = 2) durante o aprendizado, calcula a distância entre os agrupamentos com antecedência e cria uma tabela de pesquisa. No momento da previsão, a distância de cada dimensão pode ser calculada em O(1) olhando para a tabela de pesquisa.
|
||||
Portanto, o número que você especifica após PQ geralmente especifica metade da dimensão do vetor.
|
||||
|
||||
Para uma descrição mais detalhada do FastScan, consulte a documentação oficial.
|
||||
https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
|
||||
|
||||
## RFlat
|
||||
RFlat é uma instrução para recalcular a distância aproximada calculada pelo FastScan com a distância exata especificada pelo terceiro argumento da Construção de Index.
|
||||
Ao obter áreas k, os pontos k*k_factor são recalculados.
|
||||
|
|
@ -0,0 +1,224 @@
|
|||
# <b>FAQ AI HUB BRASIL</b>
|
||||
## <span style="color: #337dff;">O que é epoch, quantos utilizar, quanto de dataset utilizar e qual à configuração interessante?</span>
|
||||
Epochs basicamente quantas vezes o seu dataset foi treinado.
|
||||
|
||||
Recomendado ler Q8 e Q9 no final dessa página pra entender mais sobre dataset e epochs
|
||||
|
||||
__**Não é uma regra, mas opinião:**__
|
||||
|
||||
### **Mangio-Crepe Hop Length**
|
||||
- 64 pra cantores e dubladores
|
||||
- 128(padrão) para os demais (editado)
|
||||
|
||||
### **Epochs e dataset**
|
||||
600epoch para cantores - --dataset entre 10 e 50 min desnecessario mais que 50 minutos--
|
||||
300epoch para os demais - --dataset entre 10 e 50 min desnecessario mais que 50 minutos--
|
||||
|
||||
### **Tom**
|
||||
magio-crepe se for audios extraído de alguma musica
|
||||
harvest se for de estúdio<hr>
|
||||
|
||||
## <span style="color: #337dff;">O que é index?</span>
|
||||
Basicamente o que define o sotaque. Quanto maior o numero, mas próximo o sotaque fica do original. Porém, quando o modelo é bem, não é necessário um index.<hr>
|
||||
|
||||
## <span style="color: #337dff;">O que significa cada sigla (pm, harvest, crepe, magio-crepe, RMVPE)?</span>
|
||||
|
||||
- pm = extração mais rápida, mas discurso de qualidade inferior;
|
||||
- harvest = graves melhores, mas extremamente lentos;
|
||||
- dio = conversão rápida mas pitch ruim;
|
||||
- crepe = melhor qualidade, mas intensivo em GPU;
|
||||
- crepe-tiny = mesma coisa que o crepe, só que com a qualidade um pouco inferior;
|
||||
- **mangio-crepe = melhor qualidade, mais otimizado; (MELHOR OPÇÃO)**
|
||||
- mangio-crepe-tiny = mesma coisa que o mangio-crepe, só que com a qualidade um pouco inferior;
|
||||
- RMVPE: um modelo robusto para estimativa de afinação vocal em música polifônica;<hr>
|
||||
|
||||
## <span style="color: #337dff;">Pra rodar localmente, quais os requisitos minimos?</span>
|
||||
Já tivemos relatos de pessoas com GTX 1050 rodando inferencia, se for treinar numa 1050 vai demorar muito mesmo e inferior a isso, normalmente da tela azul
|
||||
|
||||
O mais importante é placa de vídeo, vram na verdade
|
||||
Se você tiver 4GB ou mais, você tem uma chance.
|
||||
|
||||
**NOS DOIS CASOS NÃO É RECOMENDADO UTILIZAR O PC ENQUANTO ESTÁ UTILIZNDO, CHANCE DE TELA AZUL É ALTA**
|
||||
### Inference
|
||||
Não é algo oficial para requisitos minimos
|
||||
- Placa de vídeo: nvidia de 4gb
|
||||
- Memoria ram: 8gb
|
||||
- CPU: ?
|
||||
- Armanezamento: 20gb (sem modelos)
|
||||
|
||||
### Treinamento de voz
|
||||
Não é algo oficial para requisitos minimos
|
||||
- Placa de vídeo: nvidia de 6gb
|
||||
- Memoria ram: 16gb
|
||||
- CPU: ?
|
||||
- Armanezamento: 20gb (sem modelos)<hr>
|
||||
|
||||
## <span style="color: #337dff;">Limite de GPU no Google Colab excedido, apenas CPU o que fazer?</span>
|
||||
Recomendamos esperar outro dia pra liberar mais 15gb ou 12 horas pra você. Ou você pode contribuir com o Google pagando algum dos planos, ai aumenta seu limite.<br>
|
||||
Utilizar apenas CPU no Google Colab demora DEMAIS.<hr>
|
||||
|
||||
|
||||
## <span style="color: #337dff;">Google Colab desconectando com muita frequencia, o que fazer?</span>
|
||||
Neste caso realmente não tem muito o que fazer. Apenas aguardar o proprietário do código corrigir ou a gente do AI HUB Brasil achar alguma solução. Isso acontece por diversos motivos, um incluindo a Google barrando o treinamento de voz.<hr>
|
||||
|
||||
## <span style="color: #337dff;">O que é Batch Size/Tamanho de lote e qual numero utilizar?</span>
|
||||
Batch Size/Tamanho do lote é basicamente quantos epoch faz ao mesmo tempo. Se por 20, ele fazer 20 epoch ao mesmo tempo e isso faz pesar mais na máquina e etc.<br>
|
||||
|
||||
No Google Colab você pode utilizar até 20 de boa.<br>
|
||||
Se rodando localmente, depende da sua placa de vídeo, começa por baixo (6) e vai testando.<hr>
|
||||
|
||||
## <span style="color: #337dff;">Sobre backup na hora do treinamento</span>
|
||||
Backup vai de cada um. Eu quando uso a ``easierGUI`` utilizo a cada 100 epoch (meu caso isolado).
|
||||
No colab, se instavel, coloque a cada 10 epoch
|
||||
Recomendo utilizarem entre 25 e 50 pra garantir.
|
||||
|
||||
Lembrando que cada arquivo geral é por volta de 50mb, então tenha muito cuidado quanto você coloca. Pois assim pode acabar lotando seu Google Drive ou seu PC.
|
||||
|
||||
Depois de finalizado, da pra apagar os epoch de backup.<hr>
|
||||
|
||||
## <span style="color: #337dff;">Como continuar da onde parou pra fazer mais epochs?</span>
|
||||
Primeira coisa que gostaria de lembrar, não necessariamente quanto mais epochs melhor. Se fizer epochs demais vai dar **overtraining** o que pode ser ruim.
|
||||
|
||||
### GUI NORMAL
|
||||
- Inicie normalmente a GUI novamente.
|
||||
- Na aba de treino utilize o MESMO nome que estava treinando, assim vai continuar o treino onde parou o ultimo backup.
|
||||
- Ignore as opções ``Processar o Conjunto de dados`` e ``Extrair Tom``
|
||||
- Antes de clicar pra treinar, arrume os epoch, bakcup e afins.
|
||||
- Obviamente tem que ser um numero maior do qu estava em epoch.
|
||||
- Backup você pode aumentar ou diminuir
|
||||
- Agora você vai ver a opção ``Carregue o caminho G do modelo base pré-treinado:`` e ``Carregue o caminho D do modelo base pré-treinado:``
|
||||
-Aqui você vai por o caminho dos modelos que estão em ``./logs/minha-voz``
|
||||
- Vai ficar algo parecido com isso ``e:/RVC/logs/minha-voz/G_0000.pth`` e ``e:/RVC/logs/minha-voz/D_0000.pth``
|
||||
-Coloque pra treinar
|
||||
|
||||
**Lembrando que a pasta logs tem que ter todos os arquivos e não somente o arquivo ``G`` e ``D``**
|
||||
|
||||
### EasierGUI
|
||||
- Inicie normalmente a easierGUI novamente.
|
||||
- Na aba de treino utilize o MESMO nome que estava treinando, assim vai continuar o treino onde parou o ultimo backup.
|
||||
- Selecione 'Treinar modelo', pode pular os 2 primeiros passos já que vamos continuar o treino.<hr><br>
|
||||
|
||||
|
||||
# <b>FAQ Original traduzido</b>
|
||||
## <b><span style="color: #337dff;">Q1: erro ffmpeg/erro utf8.</span></b>
|
||||
Provavelmente não é um problema do FFmpeg, mas sim um problema de caminho de áudio;
|
||||
|
||||
O FFmpeg pode encontrar um erro ao ler caminhos contendo caracteres especiais como spaces e (), o que pode causar um erro FFmpeg; e quando o áudio do conjunto de treinamento contém caminhos chineses, gravá-lo em filelist.txt pode causar um erro utf8.<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q2:Não é possível encontrar o arquivo de Index após "Treinamento com um clique".</span></b>
|
||||
Se exibir "O treinamento está concluído. O programa é fechado ", então o modelo foi treinado com sucesso e os erros subsequentes são falsos;
|
||||
|
||||
A falta de um arquivo de index 'adicionado' após o treinamento com um clique pode ser devido ao conjunto de treinamento ser muito grande, fazendo com que a adição do index fique presa; isso foi resolvido usando o processamento em lote para adicionar o index, o que resolve o problema de sobrecarga de memória ao adicionar o index. Como solução temporária, tente clicar no botão "Treinar Index" novamente.<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q3:Não é possível encontrar o modelo em “Modelo de voz” após o treinamento</span></b>
|
||||
Clique em "Atualizar lista de voz" ou "Atualizar na EasyGUI e verifique novamente; se ainda não estiver visível, verifique se há erros durante o treinamento e envie capturas de tela do console, da interface do usuário da Web e dos ``logs/experiment_name/*.log`` para os desenvolvedores para análise posterior.<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q4:Como compartilhar um modelo/Como usar os modelos dos outros?</span></b>
|
||||
Os arquivos ``.pth`` armazenados em ``*/logs/minha-voz`` não são destinados para compartilhamento ou inference, mas para armazenar os checkpoits do experimento para reprodutibilidade e treinamento adicional. O modelo a ser compartilhado deve ser o arquivo ``.pth`` de 60+MB na pasta **weights**;
|
||||
|
||||
No futuro, ``weights/minha-voz.pth`` e ``logs/minha-voz/added_xxx.index`` serão mesclados em um único arquivo de ``weights/minha-voz.zip`` para eliminar a necessidade de entrada manual de index; portanto, compartilhe o arquivo zip, não somente o arquivo .pth, a menos que você queira continuar treinando em uma máquina diferente;
|
||||
|
||||
Copiar/compartilhar os vários arquivos .pth de centenas de MB da pasta de logs para a pasta de weights para inference forçada pode resultar em erros como falta de f0, tgt_sr ou outras chaves. Você precisa usar a guia ckpt na parte inferior para manualmente ou automaticamente (se as informações forem encontradas nos ``logs/minha-voz``), selecione se deseja incluir informações de tom e opções de taxa de amostragem de áudio de destino e, em seguida, extrair o modelo menor. Após a extração, haverá um arquivo pth de 60+ MB na pasta de weights, e você pode atualizar as vozes para usá-lo.<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q5 Erro de conexão:</span></b>
|
||||
Para sermos otimistas, aperte F5/recarregue a página, pode ter sido apenas um bug da GUI
|
||||
|
||||
Se não...
|
||||
Você pode ter fechado o console (janela de linha de comando preta).
|
||||
Ou o Google Colab, no caso do Colab, as vezes pode simplesmente fechar<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q6: Pop-up WebUI 'Valor esperado: linha 1 coluna 1 (caractere 0)'.</span></b>
|
||||
Desative o proxy LAN do sistema/proxy global e atualize.<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q7:Como treinar e inferir sem a WebUI?</span></b>
|
||||
Script de treinamento:
|
||||
<br>Você pode executar o treinamento em WebUI primeiro, e as versões de linha de comando do pré-processamento e treinamento do conjunto de dados serão exibidas na janela de mensagens.<br>
|
||||
|
||||
Script de inference:
|
||||
<br>https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py<br>
|
||||
|
||||
|
||||
por exemplo<br>
|
||||
|
||||
``runtime\python.exe myinfer.py 0 "E:\audios\1111.wav" "E:\RVC\logs\minha-voz\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True``<br>
|
||||
|
||||
|
||||
f0up_key=sys.argv[1]<br>
|
||||
input_path=sys.argv[2]<br>
|
||||
index_path=sys.argv[3]<br>
|
||||
f0method=sys.argv[4]#harvest or pm<br>
|
||||
opt_path=sys.argv[5]<br>
|
||||
model_path=sys.argv[6]<br>
|
||||
index_rate=float(sys.argv[7])<br>
|
||||
device=sys.argv[8]<br>
|
||||
is_half=bool(sys.argv[9])<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q8: Erro Cuda/Cuda sem memória.</span></b>
|
||||
Há uma pequena chance de que haja um problema com a configuração do CUDA ou o dispositivo não seja suportado; mais provavelmente, não há memória suficiente (falta de memória).<br>
|
||||
|
||||
Para treinamento, reduza o (batch size) tamanho do lote (se reduzir para 1 ainda não for suficiente, talvez seja necessário alterar a placa gráfica); para inference, ajuste as configurações x_pad, x_query, x_center e x_max no arquivo config.py conforme necessário. Cartões de memória 4G ou inferiores (por exemplo, 1060(3G) e várias placas 2G) podem ser abandonados, enquanto os placas de vídeo com memória 4G ainda têm uma chance.<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q9:Quantos total_epoch são ótimos?</span></b>
|
||||
Se a qualidade de áudio do conjunto de dados de treinamento for ruim e o nível de ruído for alto, **20-30 epochs** são suficientes. Defini-lo muito alto não melhorará a qualidade de áudio do seu conjunto de treinamento de baixa qualidade.<br>
|
||||
|
||||
Se a qualidade de áudio do conjunto de treinamento for alta, o nível de ruído for baixo e houver duração suficiente, você poderá aumentá-lo. **200 é aceitável** (uma vez que o treinamento é rápido e, se você puder preparar um conjunto de treinamento de alta qualidade, sua GPU provavelmente poderá lidar com uma duração de treinamento mais longa sem problemas).<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q10:Quanto tempo de treinamento é necessário?</span></b>
|
||||
|
||||
**Recomenda-se um conjunto de dados de cerca de 10 min a 50 min.**<br>
|
||||
|
||||
Com garantia de alta qualidade de som e baixo ruído de fundo, mais pode ser adicionado se o timbre do conjunto de dados for uniforme.<br>
|
||||
|
||||
Para um conjunto de treinamento de alto nível (limpo + distintivo), 5min a 10min é bom.<br>
|
||||
|
||||
Há algumas pessoas que treinaram com sucesso com dados de 1 a 2 minutos, mas o sucesso não é reproduzível por outros e não é muito informativo. <br>Isso requer que o conjunto de treinamento tenha um timbre muito distinto (por exemplo, um som de menina de anime arejado de alta frequência) e a qualidade do áudio seja alta;
|
||||
Dados com menos de 1 minuto, já obtivemo sucesso. Mas não é recomendado.<hr>
|
||||
|
||||
|
||||
## <b><span style="color: #337dff;">Q11:Qual é a taxa do index e como ajustá-la?</span></b>
|
||||
Se a qualidade do tom do modelo pré-treinado e da fonte de inference for maior do que a do conjunto de treinamento, eles podem trazer a qualidade do tom do resultado do inference, mas ao custo de um possível viés de tom em direção ao tom do modelo subjacente/fonte de inference, em vez do tom do conjunto de treinamento, que é geralmente referido como "vazamento de tom".<br>
|
||||
|
||||
A taxa de index é usada para reduzir/resolver o problema de vazamento de timbre. Se a taxa do index for definida como 1, teoricamente não há vazamento de timbre da fonte de inference e a qualidade do timbre é mais tendenciosa em relação ao conjunto de treinamento. Se o conjunto de treinamento tiver uma qualidade de som mais baixa do que a fonte de inference, uma taxa de index mais alta poderá reduzir a qualidade do som. Reduzi-lo a 0 não tem o efeito de usar a mistura de recuperação para proteger os tons definidos de treinamento.<br>
|
||||
|
||||
Se o conjunto de treinamento tiver boa qualidade de áudio e longa duração, aumente o total_epoch, quando o modelo em si é menos propenso a se referir à fonte inferida e ao modelo subjacente pré-treinado, e há pouco "vazamento de tom", o index_rate não é importante e você pode até não criar/compartilhar o arquivo de index.<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q12:Como escolher o GPU ao inferir?</span></b>
|
||||
No arquivo ``config.py``, selecione o número da placa em "device cuda:".<br>
|
||||
|
||||
O mapeamento entre o número da placa e a placa gráfica pode ser visto na seção de informações da placa gráfica da guia de treinamento.<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q13:Como usar o modelo salvo no meio do treinamento?</span></b>
|
||||
Salvar via extração de modelo na parte inferior da guia de processamento do ckpt.<hr>
|
||||
|
||||
## <b><span style="color: #337dff;">Q14: Erro de arquivo/memória (durante o treinamento)?</span></b>
|
||||
Muitos processos e sua memória não é suficiente. Você pode corrigi-lo por:
|
||||
|
||||
1. Diminuir a entrada no campo "Threads da CPU".
|
||||
2. Diminuir o tamanho do conjunto de dados.
|
||||
|
||||
## Q15: Como continuar treinando usando mais dados
|
||||
|
||||
passo 1: coloque todos os dados wav no path2.
|
||||
|
||||
etapa 2: exp_name2 + path2 -> processar conjunto de dados e extrair recurso.
|
||||
|
||||
passo 3: copie o arquivo G e D mais recente de exp_name1 (seu experimento anterior) para a pasta exp_name2.
|
||||
|
||||
passo 4: clique em "treinar o modelo" e ele continuará treinando desde o início da época anterior do modelo exp.
|
||||
|
||||
## Q16: erro sobre llvmlite.dll
|
||||
|
||||
OSError: Não foi possível carregar o arquivo de objeto compartilhado: llvmlite.dll
|
||||
|
||||
FileNotFoundError: Não foi possível encontrar o módulo lib\site-packages\llvmlite\binding\llvmlite.dll (ou uma de suas dependências). Tente usar o caminho completo com sintaxe de construtor.
|
||||
|
||||
O problema acontecerá no Windows, instale https://aka.ms/vs/17/release/vc_redist.x64.exe e será corrigido.
|
||||
|
||||
## Q17: RuntimeError: O tamanho expandido do tensor (17280) deve corresponder ao tamanho existente (0) na dimensão 1 não singleton. Tamanhos de destino: [1, 17280]. Tamanhos de tensor: [0]
|
||||
|
||||
Exclua os arquivos wav cujo tamanho seja significativamente menor que outros e isso não acontecerá novamente. Em seguida, clique em "treinar o modelo" e "treinar o índice".
|
||||
|
||||
## Q18: RuntimeError: O tamanho do tensor a (24) deve corresponder ao tamanho do tensor b (16) na dimensão não singleton 2
|
||||
|
||||
Não altere a taxa de amostragem e continue o treinamento. Caso seja necessário alterar, o nome do exp deverá ser alterado e o modelo será treinado do zero. Você também pode copiar o pitch e os recursos (pastas 0/1/2/2b) extraídos da última vez para acelerar o processo de treinamento.
|
||||
|
||||
|
|
@ -0,0 +1,65 @@
|
|||
Instruções e dicas para treinamento RVC
|
||||
======================================
|
||||
Estas DICAS explicam como o treinamento de dados é feito.
|
||||
|
||||
# Fluxo de treinamento
|
||||
Explicarei ao longo das etapas na guia de treinamento da GUI.
|
||||
|
||||
## Passo 1
|
||||
Defina o nome do experimento aqui.
|
||||
|
||||
Você também pode definir aqui se o modelo deve levar em consideração o pitch.
|
||||
Se o modelo não considerar o tom, o modelo será mais leve, mas não será adequado para cantar.
|
||||
|
||||
Os dados de cada experimento são colocados em `/logs/nome-do-seu-modelo/`.
|
||||
|
||||
## Passo 2a
|
||||
Carrega e pré-processa áudio.
|
||||
|
||||
### Carregar áudio
|
||||
Se você especificar uma pasta com áudio, os arquivos de áudio dessa pasta serão lidos automaticamente.
|
||||
Por exemplo, se você especificar `C:Users\hoge\voices`, `C:Users\hoge\voices\voice.mp3` será carregado, mas `C:Users\hoge\voices\dir\voice.mp3` será Não carregado.
|
||||
|
||||
Como o ffmpeg é usado internamente para leitura de áudio, se a extensão for suportada pelo ffmpeg, ela será lida automaticamente.
|
||||
Após converter para int16 com ffmpeg, converta para float32 e normalize entre -1 e 1.
|
||||
|
||||
### Eliminar ruído
|
||||
O áudio é suavizado pelo filtfilt do scipy.
|
||||
|
||||
### Divisão de áudio
|
||||
Primeiro, o áudio de entrada é dividido pela detecção de partes de silêncio que duram mais que um determinado período (max_sil_kept=5 segundos?). Após dividir o áudio no silêncio, divida o áudio a cada 4 segundos com uma sobreposição de 0,3 segundos. Para áudio separado em 4 segundos, após normalizar o volume, converta o arquivo wav para `/logs/nome-do-seu-modelo/0_gt_wavs` e, em seguida, converta-o para taxa de amostragem de 16k para `/logs/nome-do-seu-modelo/1_16k_wavs ` como um arquivo wav.
|
||||
|
||||
## Passo 2b
|
||||
### Extrair pitch
|
||||
Extraia informações de pitch de arquivos wav. Extraia as informações de pitch (=f0) usando o método incorporado em Parselmouth ou pyworld e salve-as em `/logs/nome-do-seu-modelo/2a_f0`. Em seguida, converta logaritmicamente as informações de pitch para um número inteiro entre 1 e 255 e salve-as em `/logs/nome-do-seu-modelo/2b-f0nsf`.
|
||||
|
||||
### Extrair feature_print
|
||||
Converta o arquivo wav para incorporação antecipadamente usando HuBERT. Leia o arquivo wav salvo em `/logs/nome-do-seu-modelo/1_16k_wavs`, converta o arquivo wav em recursos de 256 dimensões com HuBERT e salve no formato npy em `/logs/nome-do-seu-modelo/3_feature256`.
|
||||
|
||||
## Passo 3
|
||||
treinar o modelo.
|
||||
### Glossário para iniciantes
|
||||
No aprendizado profundo, o conjunto de dados é dividido e o aprendizado avança aos poucos. Em uma atualização do modelo (etapa), os dados batch_size são recuperados e previsões e correções de erros são realizadas. Fazer isso uma vez para um conjunto de dados conta como um epoch.
|
||||
|
||||
Portanto, o tempo de aprendizagem é o tempo de aprendizagem por etapa x (o número de dados no conjunto de dados/tamanho do lote) x o número de epoch. Em geral, quanto maior o tamanho do lote, mais estável se torna o aprendizado (tempo de aprendizado por etapa ÷ tamanho do lote) fica menor, mas usa mais memória GPU. A RAM da GPU pode ser verificada com o comando nvidia-smi. O aprendizado pode ser feito em pouco tempo aumentando o tamanho do lote tanto quanto possível de acordo com a máquina do ambiente de execução.
|
||||
|
||||
### Especifique o modelo pré-treinado
|
||||
O RVC começa a treinar o modelo a partir de pesos pré-treinados em vez de 0, para que possa ser treinado com um pequeno conjunto de dados.
|
||||
|
||||
Por padrão
|
||||
|
||||
- Se você considerar o pitch, ele carrega `rvc-location/pretrained/f0G40k.pth` e `rvc-location/pretrained/f0D40k.pth`.
|
||||
- Se você não considerar o pitch, ele carrega `rvc-location/pretrained/f0G40k.pth` e `rvc-location/pretrained/f0D40k.pth`.
|
||||
|
||||
Ao aprender, os parâmetros do modelo são salvos em `logs/nome-do-seu-modelo/G_{}.pth` e `logs/nome-do-seu-modelo/D_{}.pth` para cada save_every_epoch, mas especificando nesse caminho, você pode começar a aprender. Você pode reiniciar ou iniciar o treinamento a partir de weights de modelo aprendidos em um experimento diferente.
|
||||
|
||||
### Index de aprendizado
|
||||
O RVC salva os valores de recursos do HuBERT usados durante o treinamento e, durante a inferência, procura valores de recursos que sejam semelhantes aos valores de recursos usados durante o aprendizado para realizar a inferência. Para realizar esta busca em alta velocidade, o index é aprendido previamente.
|
||||
Para aprendizagem de index, usamos a biblioteca de pesquisa de associação de áreas aproximadas faiss. Leia o valor do recurso `logs/nome-do-seu-modelo/3_feature256` e use-o para aprender o index, e salve-o como `logs/nome-do-seu-modelo/add_XXX.index`.
|
||||
|
||||
(A partir da versão 20230428update, ele é lido do index e não é mais necessário salvar/especificar.)
|
||||
|
||||
### Descrição do botão
|
||||
- Treinar modelo: Após executar o passo 2b, pressione este botão para treinar o modelo.
|
||||
- Treinar índice de recursos: após treinar o modelo, execute o aprendizado do index.
|
||||
- Treinamento com um clique: etapa 2b, treinamento de modelo e treinamento de index de recursos, tudo de uma vez.
|
||||
|
|
@ -20,7 +20,7 @@ VITS'e dayalı kullanımı kolay bir Ses Dönüşümü çerçevesi.<br><br>
|
|||
------
|
||||
[**Değişiklik Geçmişi**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_TR.md) | [**SSS (Sıkça Sorulan Sorular)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/SSS-(Sıkça-Sorulan-Sorular))
|
||||
|
||||
[**İngilizce**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
||||
[**İngilizce**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Français**](../fr/README.fr.md) | [**Türkçe**](../tr/README.tr.md)
|
||||
|
||||
Burada [Demo Video'muzu](https://www.bilibili.com/video/BV1pm4y1z7Gm/) izleyebilirsiniz!
|
||||
|
||||
|
|
|
|||
BIN
docs/小白简易教程.doc
BIN
docs/小白简易教程.doc
Binary file not shown.
441
gui_v1.py
441
gui_v1.py
|
|
@ -12,7 +12,7 @@ now_dir = os.getcwd()
|
|||
sys.path.append(now_dir)
|
||||
import multiprocessing
|
||||
|
||||
stream_latency = -1
|
||||
flag_vc = False
|
||||
|
||||
|
||||
def printt(strr, *args):
|
||||
|
|
@ -38,10 +38,14 @@ def phase_vocoder(a, b, fade_out, fade_in):
|
|||
deltaphase = deltaphase - 2 * np.pi * torch.floor(deltaphase / 2 / np.pi + 0.5)
|
||||
w = 2 * np.pi * torch.arange(n // 2 + 1).to(a) + deltaphase
|
||||
t = torch.arange(n).unsqueeze(-1).to(a) / n
|
||||
result = a * (fade_out ** 2) + b * (fade_in ** 2) + torch.sum(absab * torch.cos(w * t + phia), -1) * window / n
|
||||
result = (
|
||||
a * (fade_out**2)
|
||||
+ b * (fade_in**2)
|
||||
+ torch.sum(absab * torch.cos(w * t + phia), -1) * window / n
|
||||
)
|
||||
return result
|
||||
|
||||
|
||||
|
||||
class Harvest(multiprocessing.Process):
|
||||
def __init__(self, inp_q, opt_q):
|
||||
multiprocessing.Process.__init__(self)
|
||||
|
|
@ -109,32 +113,39 @@ if __name__ == "__main__":
|
|||
self.pth_path: str = ""
|
||||
self.index_path: str = ""
|
||||
self.pitch: int = 0
|
||||
self.samplerate: int = 40000
|
||||
self.block_time: float = 1.0 # s
|
||||
self.buffer_num: int = 1
|
||||
self.sr_type: str = "sr_model"
|
||||
self.block_time: float = 0.25 # s
|
||||
self.threhold: int = -60
|
||||
self.crossfade_time: float = 0.05
|
||||
self.extra_time: float = 2.5
|
||||
self.I_noise_reduce = False
|
||||
self.O_noise_reduce = False
|
||||
self.rms_mix_rate = 0.0
|
||||
self.index_rate = 0.3
|
||||
self.n_cpu = min(n_cpu, 6)
|
||||
self.f0method = "harvest"
|
||||
self.sg_input_device = ""
|
||||
self.sg_output_device = ""
|
||||
self.I_noise_reduce: bool = False
|
||||
self.O_noise_reduce: bool = False
|
||||
self.use_pv: bool = False
|
||||
self.rms_mix_rate: float = 0.0
|
||||
self.index_rate: float = 0.0
|
||||
self.n_cpu: int = min(n_cpu, 4)
|
||||
self.f0method: str = "fcpe"
|
||||
self.sg_hostapi: str = ""
|
||||
self.wasapi_exclusive: bool = False
|
||||
self.sg_input_device: str = ""
|
||||
self.sg_output_device: str = ""
|
||||
|
||||
class GUI:
|
||||
def __init__(self) -> None:
|
||||
self.gui_config = GUIConfig()
|
||||
self.config = Config()
|
||||
self.flag_vc = False
|
||||
self.function = "vc"
|
||||
self.delay_time = 0
|
||||
self.hostapis = None
|
||||
self.input_devices = None
|
||||
self.output_devices = None
|
||||
self.input_devices_indices = None
|
||||
self.output_devices_indices = None
|
||||
self.stream = None
|
||||
self.update_devices()
|
||||
self.launcher()
|
||||
|
||||
def load(self):
|
||||
input_devices, output_devices, _, _ = self.get_devices()
|
||||
try:
|
||||
with open("configs/config.json", "r") as j:
|
||||
data = json.load(j)
|
||||
|
|
@ -145,25 +156,50 @@ if __name__ == "__main__":
|
|||
data["crepe"] = data["f0method"] == "crepe"
|
||||
data["rmvpe"] = data["f0method"] == "rmvpe"
|
||||
data["fcpe"] = data["f0method"] == "fcpe"
|
||||
if data["sg_input_device"] not in input_devices:
|
||||
data["sg_input_device"] = input_devices[sd.default.device[0]]
|
||||
if data["sg_output_device"] not in output_devices:
|
||||
data["sg_output_device"] = output_devices[sd.default.device[1]]
|
||||
if data["sg_hostapi"] in self.hostapis:
|
||||
self.update_devices(hostapi_name=data["sg_hostapi"])
|
||||
if (
|
||||
data["sg_input_device"] not in self.input_devices
|
||||
or data["sg_output_device"] not in self.output_devices
|
||||
):
|
||||
self.update_devices()
|
||||
data["sg_hostapi"] = self.hostapis[0]
|
||||
data["sg_input_device"] = self.input_devices[
|
||||
self.input_devices_indices.index(sd.default.device[0])
|
||||
]
|
||||
data["sg_output_device"] = self.output_devices[
|
||||
self.output_devices_indices.index(sd.default.device[1])
|
||||
]
|
||||
else:
|
||||
data["sg_hostapi"] = self.hostapis[0]
|
||||
data["sg_input_device"] = self.input_devices[
|
||||
self.input_devices_indices.index(sd.default.device[0])
|
||||
]
|
||||
data["sg_output_device"] = self.output_devices[
|
||||
self.output_devices_indices.index(sd.default.device[1])
|
||||
]
|
||||
except:
|
||||
with open("configs/config.json", "w") as j:
|
||||
data = {
|
||||
"pth_path": " ",
|
||||
"index_path": " ",
|
||||
"sg_input_device": input_devices[sd.default.device[0]],
|
||||
"sg_output_device": output_devices[sd.default.device[1]],
|
||||
"pth_path": "",
|
||||
"index_path": "",
|
||||
"sg_hostapi": self.hostapis[0],
|
||||
"sg_wasapi_exclusive": False,
|
||||
"sg_input_device": self.input_devices[
|
||||
self.input_devices_indices.index(sd.default.device[0])
|
||||
],
|
||||
"sg_output_device": self.output_devices[
|
||||
self.output_devices_indices.index(sd.default.device[1])
|
||||
],
|
||||
"sr_type": "sr_model",
|
||||
"threhold": "-60",
|
||||
"pitch": "0",
|
||||
"index_rate": "0",
|
||||
"rms_mix_rate": "0",
|
||||
"block_time": "0.25",
|
||||
"crossfade_length": "0.05",
|
||||
"extra_time": "2.5",
|
||||
"threhold": -60,
|
||||
"pitch": 0,
|
||||
"index_rate": 0,
|
||||
"rms_mix_rate": 0,
|
||||
"block_time": 0.25,
|
||||
"crossfade_length": 0.05,
|
||||
"extra_time": 2.5,
|
||||
"n_cpu": 4,
|
||||
"f0method": "rmvpe",
|
||||
"use_jit": False,
|
||||
"use_pv": False,
|
||||
|
|
@ -181,7 +217,6 @@ if __name__ == "__main__":
|
|||
data = self.load()
|
||||
self.config.use_jit = False # data.get("use_jit", self.config.use_jit)
|
||||
sg.theme("LightBlue3")
|
||||
input_devices, output_devices, _, _ = self.get_devices()
|
||||
layout = [
|
||||
[
|
||||
sg.Frame(
|
||||
|
|
@ -217,20 +252,40 @@ if __name__ == "__main__":
|
|||
[
|
||||
sg.Frame(
|
||||
layout=[
|
||||
[
|
||||
sg.Text(i18n("设备类型")),
|
||||
sg.Combo(
|
||||
self.hostapis,
|
||||
key="sg_hostapi",
|
||||
default_value=data.get("sg_hostapi", ""),
|
||||
enable_events=True,
|
||||
size=(20, 1),
|
||||
),
|
||||
sg.Checkbox(
|
||||
i18n("独占 WASAPI 设备"),
|
||||
key="sg_wasapi_exclusive",
|
||||
default=data.get("sg_wasapi_exclusive", False),
|
||||
enable_events=True,
|
||||
),
|
||||
],
|
||||
[
|
||||
sg.Text(i18n("输入设备")),
|
||||
sg.Combo(
|
||||
input_devices,
|
||||
self.input_devices,
|
||||
key="sg_input_device",
|
||||
default_value=data.get("sg_input_device", ""),
|
||||
enable_events=True,
|
||||
size=(45, 1),
|
||||
),
|
||||
],
|
||||
[
|
||||
sg.Text(i18n("输出设备")),
|
||||
sg.Combo(
|
||||
output_devices,
|
||||
self.output_devices,
|
||||
key="sg_output_device",
|
||||
default_value=data.get("sg_output_device", ""),
|
||||
enable_events=True,
|
||||
size=(45, 1),
|
||||
),
|
||||
],
|
||||
[
|
||||
|
|
@ -253,7 +308,7 @@ if __name__ == "__main__":
|
|||
sg.Text("", key="sr_stream"),
|
||||
],
|
||||
],
|
||||
title=i18n("音频设备(请使用同种类驱动)"),
|
||||
title=i18n("音频设备"),
|
||||
)
|
||||
],
|
||||
[
|
||||
|
|
@ -349,7 +404,7 @@ if __name__ == "__main__":
|
|||
[
|
||||
sg.Text(i18n("采样长度")),
|
||||
sg.Slider(
|
||||
range=(0.02, 2.4),
|
||||
range=(0.02, 1.5),
|
||||
key="block_time",
|
||||
resolution=0.01,
|
||||
orientation="h",
|
||||
|
|
@ -459,38 +514,40 @@ if __name__ == "__main__":
|
|||
self.event_handler()
|
||||
|
||||
def event_handler(self):
|
||||
global flag_vc
|
||||
while True:
|
||||
event, values = self.window.read()
|
||||
if event == sg.WINDOW_CLOSED:
|
||||
self.flag_vc = False
|
||||
self.stop_stream()
|
||||
exit()
|
||||
if event == "reload_devices":
|
||||
prev_input = self.window["sg_input_device"].get()
|
||||
prev_output = self.window["sg_output_device"].get()
|
||||
input_devices, output_devices, _, _ = self.get_devices(update=True)
|
||||
if prev_input not in input_devices:
|
||||
self.gui_config.sg_input_device = input_devices[0]
|
||||
else:
|
||||
self.gui_config.sg_input_device = prev_input
|
||||
self.window["sg_input_device"].Update(values=input_devices)
|
||||
if event == "reload_devices" or event == "sg_hostapi":
|
||||
self.gui_config.sg_hostapi = values["sg_hostapi"]
|
||||
self.update_devices(hostapi_name=values["sg_hostapi"])
|
||||
if self.gui_config.sg_hostapi not in self.hostapis:
|
||||
self.gui_config.sg_hostapi = self.hostapis[0]
|
||||
self.window["sg_hostapi"].Update(values=self.hostapis)
|
||||
self.window["sg_hostapi"].Update(value=self.gui_config.sg_hostapi)
|
||||
if self.gui_config.sg_input_device not in self.input_devices:
|
||||
self.gui_config.sg_input_device = self.input_devices[0]
|
||||
self.window["sg_input_device"].Update(values=self.input_devices)
|
||||
self.window["sg_input_device"].Update(
|
||||
value=self.gui_config.sg_input_device
|
||||
)
|
||||
if prev_output not in output_devices:
|
||||
self.gui_config.sg_output_device = output_devices[0]
|
||||
else:
|
||||
self.gui_config.sg_output_device = prev_output
|
||||
self.window["sg_output_device"].Update(values=output_devices)
|
||||
if self.gui_config.sg_output_device not in self.output_devices:
|
||||
self.gui_config.sg_output_device = self.output_devices[0]
|
||||
self.window["sg_output_device"].Update(values=self.output_devices)
|
||||
self.window["sg_output_device"].Update(
|
||||
value=self.gui_config.sg_output_device
|
||||
)
|
||||
if event == "start_vc" and self.flag_vc == False:
|
||||
if event == "start_vc" and not flag_vc:
|
||||
if self.set_values(values) == True:
|
||||
printt("cuda_is_available: %s", torch.cuda.is_available())
|
||||
self.start_vc()
|
||||
settings = {
|
||||
"pth_path": values["pth_path"],
|
||||
"index_path": values["index_path"],
|
||||
"sg_hostapi": values["sg_hostapi"],
|
||||
"sg_wasapi_exclusive": values["sg_wasapi_exclusive"],
|
||||
"sg_input_device": values["sg_input_device"],
|
||||
"sg_output_device": values["sg_output_device"],
|
||||
"sr_type": ["sr_model", "sr_device"][
|
||||
|
|
@ -523,22 +580,19 @@ if __name__ == "__main__":
|
|||
}
|
||||
with open("configs/config.json", "w") as j:
|
||||
json.dump(settings, j)
|
||||
global stream_latency
|
||||
while stream_latency < 0:
|
||||
time.sleep(0.01)
|
||||
self.delay_time = (
|
||||
stream_latency
|
||||
+ values["block_time"]
|
||||
+ values["crossfade_length"]
|
||||
+ 0.01
|
||||
)
|
||||
if self.stream is not None:
|
||||
self.delay_time = (
|
||||
self.stream.latency[-1]
|
||||
+ values["block_time"]
|
||||
+ values["crossfade_length"]
|
||||
+ 0.01
|
||||
)
|
||||
if values["I_noise_reduce"]:
|
||||
self.delay_time += min(values["crossfade_length"], 0.04)
|
||||
self.window["sr_stream"].update(self.gui_config.samplerate)
|
||||
self.window["delay_time"].update(int(self.delay_time * 1000))
|
||||
if event == "stop_vc" and self.flag_vc == True:
|
||||
self.flag_vc = False
|
||||
stream_latency = -1
|
||||
self.window["delay_time"].update(
|
||||
int(np.round(self.delay_time * 1000))
|
||||
)
|
||||
# Parameter hot update
|
||||
if event == "threhold":
|
||||
self.gui_config.threhold = values["threhold"]
|
||||
|
|
@ -556,21 +610,22 @@ if __name__ == "__main__":
|
|||
self.gui_config.f0method = event
|
||||
elif event == "I_noise_reduce":
|
||||
self.gui_config.I_noise_reduce = values["I_noise_reduce"]
|
||||
if stream_latency > 0:
|
||||
if self.stream is not None:
|
||||
self.delay_time += (
|
||||
1 if values["I_noise_reduce"] else -1
|
||||
) * min(values["crossfade_length"], 0.04)
|
||||
self.window["delay_time"].update(int(self.delay_time * 1000))
|
||||
self.window["delay_time"].update(
|
||||
int(np.round(self.delay_time * 1000))
|
||||
)
|
||||
elif event == "O_noise_reduce":
|
||||
self.gui_config.O_noise_reduce = values["O_noise_reduce"]
|
||||
elif event == "use_pv":
|
||||
self.gui_config.use_pv = values["use_pv"]
|
||||
elif event in ["vc", "im"]:
|
||||
self.function = event
|
||||
elif event != "start_vc" and self.flag_vc == True:
|
||||
elif event == "stop_vc" or event != "start_vc":
|
||||
# Other parameters do not support hot update
|
||||
self.flag_vc = False
|
||||
stream_latency = -1
|
||||
self.stop_stream()
|
||||
|
||||
def set_values(self, values):
|
||||
if len(values["pth_path"].strip()) == 0:
|
||||
|
|
@ -589,14 +644,18 @@ if __name__ == "__main__":
|
|||
self.set_devices(values["sg_input_device"], values["sg_output_device"])
|
||||
self.config.use_jit = False # values["use_jit"]
|
||||
# self.device_latency = values["device_latency"]
|
||||
self.gui_config.sg_hostapi = values["sg_hostapi"]
|
||||
self.gui_config.sg_wasapi_exclusive = values["sg_wasapi_exclusive"]
|
||||
self.gui_config.sg_input_device = values["sg_input_device"]
|
||||
self.gui_config.sg_output_device = values["sg_output_device"]
|
||||
self.gui_config.pth_path = values["pth_path"]
|
||||
self.gui_config.index_path = values["index_path"]
|
||||
self.gui_config.sr_type = ["sr_model", "sr_device"][
|
||||
[
|
||||
values["sr_model"],
|
||||
values["sr_device"],
|
||||
].index(True)
|
||||
]
|
||||
[
|
||||
values["sr_model"],
|
||||
values["sr_device"],
|
||||
].index(True)
|
||||
]
|
||||
self.gui_config.threhold = values["threhold"]
|
||||
self.gui_config.pitch = values["pitch"]
|
||||
self.gui_config.block_time = values["block_time"]
|
||||
|
|
@ -621,7 +680,6 @@ if __name__ == "__main__":
|
|||
|
||||
def start_vc(self):
|
||||
torch.cuda.empty_cache()
|
||||
self.flag_vc = True
|
||||
self.rvc = rvc_for_realtime.RVC(
|
||||
self.gui_config.pitch,
|
||||
self.gui_config.pth_path,
|
||||
|
|
@ -633,7 +691,12 @@ if __name__ == "__main__":
|
|||
self.config,
|
||||
self.rvc if hasattr(self, "rvc") else None,
|
||||
)
|
||||
self.gui_config.samplerate = self.rvc.tgt_sr if self.gui_config.sr_type == "sr_model" else self.get_device_samplerate()
|
||||
self.gui_config.samplerate = (
|
||||
self.rvc.tgt_sr
|
||||
if self.gui_config.sr_type == "sr_model"
|
||||
else self.get_device_samplerate()
|
||||
)
|
||||
self.gui_config.channels = self.get_device_channels()
|
||||
self.zc = self.gui_config.samplerate // 100
|
||||
self.block_frame = (
|
||||
int(
|
||||
|
|
@ -676,21 +739,22 @@ if __name__ == "__main__":
|
|||
device=self.config.device,
|
||||
dtype=torch.float32,
|
||||
)
|
||||
self.input_wav_denoise: torch.Tensor = self.input_wav.clone()
|
||||
self.input_wav_res: torch.Tensor = torch.zeros(
|
||||
160 * self.input_wav.shape[0] // self.zc,
|
||||
device=self.config.device,
|
||||
dtype=torch.float32,
|
||||
)
|
||||
self.rms_buffer: np.ndarray = np.zeros(4 * self.zc, dtype="float32")
|
||||
self.sola_buffer: torch.Tensor = torch.zeros(
|
||||
self.sola_buffer_frame, device=self.config.device, dtype=torch.float32
|
||||
)
|
||||
self.nr_buffer: torch.Tensor = self.sola_buffer.clone()
|
||||
self.output_buffer: torch.Tensor = self.input_wav.clone()
|
||||
self.res_buffer: torch.Tensor = torch.zeros(
|
||||
2 * self.zc, device=self.config.device, dtype=torch.float32
|
||||
)
|
||||
self.skip_head = self.extra_frame // self.zc
|
||||
self.return_length = (self.block_frame + self.sola_buffer_frame + self.sola_search_frame) // self.zc
|
||||
self.return_length = (
|
||||
self.block_frame + self.sola_buffer_frame + self.sola_search_frame
|
||||
) // self.zc
|
||||
self.fade_in_window: torch.Tensor = (
|
||||
torch.sin(
|
||||
0.5
|
||||
|
|
@ -722,27 +786,37 @@ if __name__ == "__main__":
|
|||
self.tg = TorchGate(
|
||||
sr=self.gui_config.samplerate, n_fft=4 * self.zc, prop_decrease=0.9
|
||||
).to(self.config.device)
|
||||
thread_vc = threading.Thread(target=self.soundinput)
|
||||
thread_vc.start()
|
||||
self.start_stream()
|
||||
|
||||
def soundinput(self):
|
||||
"""
|
||||
接受音频输入
|
||||
"""
|
||||
channels = 1 if sys.platform == "darwin" else 2
|
||||
with sd.Stream(
|
||||
channels=channels,
|
||||
callback=self.audio_callback,
|
||||
blocksize=self.block_frame,
|
||||
samplerate=self.gui_config.samplerate,
|
||||
dtype="float32",
|
||||
) as stream:
|
||||
global stream_latency
|
||||
stream_latency = stream.latency[-1]
|
||||
while self.flag_vc:
|
||||
time.sleep(self.gui_config.block_time)
|
||||
printt("Audio block passed.")
|
||||
printt("ENDing VC")
|
||||
def start_stream(self):
|
||||
global flag_vc
|
||||
if not flag_vc:
|
||||
flag_vc = True
|
||||
if (
|
||||
"WASAPI" in self.gui_config.sg_hostapi
|
||||
and self.gui_config.sg_wasapi_exclusive
|
||||
):
|
||||
extra_settings = sd.WasapiSettings(exclusive=True)
|
||||
else:
|
||||
extra_settings = None
|
||||
self.stream = sd.Stream(
|
||||
callback=self.audio_callback,
|
||||
blocksize=self.block_frame,
|
||||
samplerate=self.gui_config.samplerate,
|
||||
channels=self.gui_config.channels,
|
||||
dtype="float32",
|
||||
extra_settings=extra_settings,
|
||||
)
|
||||
self.stream.start()
|
||||
|
||||
def stop_stream(self):
|
||||
global flag_vc
|
||||
if flag_vc:
|
||||
flag_vc = False
|
||||
if self.stream is not None:
|
||||
self.stream.abort()
|
||||
self.stream.close()
|
||||
self.stream = None
|
||||
|
||||
def audio_callback(
|
||||
self, indata: np.ndarray, outdata: np.ndarray, frames, times, status
|
||||
|
|
@ -750,51 +824,58 @@ if __name__ == "__main__":
|
|||
"""
|
||||
音频处理
|
||||
"""
|
||||
global flag_vc
|
||||
start_time = time.perf_counter()
|
||||
indata = librosa.to_mono(indata.T)
|
||||
if self.gui_config.threhold > -60:
|
||||
indata = np.append(self.rms_buffer, indata)
|
||||
rms = librosa.feature.rms(
|
||||
y=indata, frame_length=4 * self.zc, hop_length=self.zc
|
||||
)
|
||||
)[:, 2:]
|
||||
self.rms_buffer[:] = indata[-4 * self.zc :]
|
||||
indata = indata[2 * self.zc - self.zc // 2 :]
|
||||
db_threhold = (
|
||||
librosa.amplitude_to_db(rms, ref=1.0)[0] < self.gui_config.threhold
|
||||
)
|
||||
for i in range(db_threhold.shape[0]):
|
||||
if db_threhold[i]:
|
||||
indata[i * self.zc : (i + 1) * self.zc] = 0
|
||||
indata = indata[self.zc // 2 :]
|
||||
self.input_wav[: -self.block_frame] = self.input_wav[
|
||||
self.block_frame :
|
||||
].clone()
|
||||
self.input_wav[-self.block_frame :] = torch.from_numpy(indata).to(
|
||||
self.input_wav[-indata.shape[0] :] = torch.from_numpy(indata).to(
|
||||
self.config.device
|
||||
)
|
||||
self.input_wav_res[: -self.block_frame_16k] = self.input_wav_res[
|
||||
self.block_frame_16k :
|
||||
].clone()
|
||||
# input noise reduction and resampling
|
||||
if self.gui_config.I_noise_reduce and self.function == "vc":
|
||||
input_wav = self.input_wav[
|
||||
-self.sola_buffer_frame - self.block_frame - 2 * self.zc :
|
||||
]
|
||||
if self.gui_config.I_noise_reduce:
|
||||
self.input_wav_denoise[: -self.block_frame] = self.input_wav_denoise[
|
||||
self.block_frame :
|
||||
].clone()
|
||||
input_wav = self.input_wav[-self.sola_buffer_frame - self.block_frame :]
|
||||
input_wav = self.tg(
|
||||
input_wav.unsqueeze(0), self.input_wav.unsqueeze(0)
|
||||
)[0, 2 * self.zc :]
|
||||
).squeeze(0)
|
||||
input_wav[: self.sola_buffer_frame] *= self.fade_in_window
|
||||
input_wav[: self.sola_buffer_frame] += (
|
||||
self.nr_buffer * self.fade_out_window
|
||||
)
|
||||
self.input_wav_denoise[-self.block_frame :] = input_wav[
|
||||
: self.block_frame
|
||||
]
|
||||
self.nr_buffer[:] = input_wav[self.block_frame :]
|
||||
input_wav = torch.cat(
|
||||
(self.res_buffer[:], input_wav[: self.block_frame])
|
||||
)
|
||||
self.res_buffer[:] = input_wav[-2 * self.zc :]
|
||||
self.input_wav_res[-self.block_frame_16k - 160 :] = self.resampler(
|
||||
input_wav
|
||||
self.input_wav_denoise[-self.block_frame - 2 * self.zc :]
|
||||
)[160:]
|
||||
else:
|
||||
self.input_wav_res[-self.block_frame_16k - 160 :] = self.resampler(
|
||||
self.input_wav[-self.block_frame - 2 * self.zc :]
|
||||
)[160:]
|
||||
self.input_wav_res[
|
||||
-160 * (indata.shape[0] // self.zc + 1) :
|
||||
] = self.resampler(self.input_wav[-indata.shape[0] - 2 * self.zc :])[
|
||||
160:
|
||||
]
|
||||
# infer
|
||||
if self.function == "vc":
|
||||
infer_wav = self.rvc.infer(
|
||||
|
|
@ -806,14 +887,12 @@ if __name__ == "__main__":
|
|||
)
|
||||
if self.resampler2 is not None:
|
||||
infer_wav = self.resampler2(infer_wav)
|
||||
elif self.gui_config.I_noise_reduce:
|
||||
infer_wav = self.input_wav_denoise[self.extra_frame :].clone()
|
||||
else:
|
||||
infer_wav = self.input_wav[
|
||||
-self.crossfade_frame - self.sola_search_frame - self.block_frame :
|
||||
].clone()
|
||||
infer_wav = self.input_wav[self.extra_frame :].clone()
|
||||
# output noise reduction
|
||||
if (self.gui_config.O_noise_reduce and self.function == "vc") or (
|
||||
self.gui_config.I_noise_reduce and self.function == "im"
|
||||
):
|
||||
if self.gui_config.O_noise_reduce and self.function == "vc":
|
||||
self.output_buffer[: -self.block_frame] = self.output_buffer[
|
||||
self.block_frame :
|
||||
].clone()
|
||||
|
|
@ -823,12 +902,14 @@ if __name__ == "__main__":
|
|||
).squeeze(0)
|
||||
# volume envelop mixing
|
||||
if self.gui_config.rms_mix_rate < 1 and self.function == "vc":
|
||||
if self.gui_config.I_noise_reduce:
|
||||
input_wav = self.input_wav_denoise[self.extra_frame :]
|
||||
else:
|
||||
input_wav = self.input_wav[self.extra_frame :]
|
||||
rms1 = librosa.feature.rms(
|
||||
y=self.input_wav_res[160 * self.skip_head : 160 * (self.skip_head + self.return_length)]
|
||||
.cpu()
|
||||
.numpy(),
|
||||
frame_length=640,
|
||||
hop_length=160,
|
||||
y=input_wav[: infer_wav.shape[0]].cpu().numpy(),
|
||||
frame_length=4 * self.zc,
|
||||
hop_length=self.zc,
|
||||
)
|
||||
rms1 = torch.from_numpy(rms1).to(self.config.device)
|
||||
rms1 = F.interpolate(
|
||||
|
|
@ -871,84 +952,92 @@ if __name__ == "__main__":
|
|||
else:
|
||||
sola_offset = torch.argmax(cor_nom[0, 0] / cor_den[0, 0])
|
||||
printt("sola_offset = %d", int(sola_offset))
|
||||
infer_wav = infer_wav[sola_offset :]
|
||||
infer_wav = infer_wav[sola_offset:]
|
||||
if "privateuseone" in str(self.config.device) or not self.gui_config.use_pv:
|
||||
infer_wav[: self.sola_buffer_frame] *= self.fade_in_window
|
||||
infer_wav[: self.sola_buffer_frame] += self.sola_buffer * self.fade_out_window
|
||||
infer_wav[: self.sola_buffer_frame] += (
|
||||
self.sola_buffer * self.fade_out_window
|
||||
)
|
||||
else:
|
||||
infer_wav[: self.sola_buffer_frame] = phase_vocoder(
|
||||
self.sola_buffer,
|
||||
infer_wav[: self.sola_buffer_frame],
|
||||
self.fade_out_window,
|
||||
self.fade_in_window)
|
||||
self.sola_buffer[:] = infer_wav[self.block_frame : self.block_frame + self.sola_buffer_frame]
|
||||
if sys.platform == "darwin":
|
||||
outdata[:] = (
|
||||
infer_wav[: self.block_frame].cpu().numpy()[:, np.newaxis]
|
||||
)
|
||||
else:
|
||||
outdata[:] = (
|
||||
infer_wav[: self.block_frame].repeat(2, 1).t().cpu().numpy()
|
||||
self.sola_buffer,
|
||||
infer_wav[: self.sola_buffer_frame],
|
||||
self.fade_out_window,
|
||||
self.fade_in_window,
|
||||
)
|
||||
self.sola_buffer[:] = infer_wav[
|
||||
self.block_frame : self.block_frame + self.sola_buffer_frame
|
||||
]
|
||||
outdata[:] = (
|
||||
infer_wav[: self.block_frame]
|
||||
.repeat(self.gui_config.channels, 1)
|
||||
.t()
|
||||
.cpu()
|
||||
.numpy()
|
||||
)
|
||||
total_time = time.perf_counter() - start_time
|
||||
self.window["infer_time"].update(int(total_time * 1000))
|
||||
if flag_vc:
|
||||
self.window["infer_time"].update(int(total_time * 1000))
|
||||
printt("Infer time: %.2f", total_time)
|
||||
|
||||
def get_devices(self, update: bool = True):
|
||||
def update_devices(self, hostapi_name=None):
|
||||
"""获取设备列表"""
|
||||
if update:
|
||||
sd._terminate()
|
||||
sd._initialize()
|
||||
global flag_vc
|
||||
flag_vc = False
|
||||
sd._terminate()
|
||||
sd._initialize()
|
||||
devices = sd.query_devices()
|
||||
hostapis = sd.query_hostapis()
|
||||
for hostapi in hostapis:
|
||||
for device_idx in hostapi["devices"]:
|
||||
devices[device_idx]["hostapi_name"] = hostapi["name"]
|
||||
input_devices = [
|
||||
f"{d['name']} ({d['hostapi_name']})"
|
||||
self.hostapis = [hostapi["name"] for hostapi in hostapis]
|
||||
if hostapi_name not in self.hostapis:
|
||||
hostapi_name = self.hostapis[0]
|
||||
self.input_devices = [
|
||||
d["name"]
|
||||
for d in devices
|
||||
if d["max_input_channels"] > 0
|
||||
if d["max_input_channels"] > 0 and d["hostapi_name"] == hostapi_name
|
||||
]
|
||||
output_devices = [
|
||||
f"{d['name']} ({d['hostapi_name']})"
|
||||
self.output_devices = [
|
||||
d["name"]
|
||||
for d in devices
|
||||
if d["max_output_channels"] > 0
|
||||
if d["max_output_channels"] > 0 and d["hostapi_name"] == hostapi_name
|
||||
]
|
||||
input_devices_indices = [
|
||||
self.input_devices_indices = [
|
||||
d["index"] if "index" in d else d["name"]
|
||||
for d in devices
|
||||
if d["max_input_channels"] > 0
|
||||
if d["max_input_channels"] > 0 and d["hostapi_name"] == hostapi_name
|
||||
]
|
||||
output_devices_indices = [
|
||||
self.output_devices_indices = [
|
||||
d["index"] if "index" in d else d["name"]
|
||||
for d in devices
|
||||
if d["max_output_channels"] > 0
|
||||
if d["max_output_channels"] > 0 and d["hostapi_name"] == hostapi_name
|
||||
]
|
||||
return (
|
||||
input_devices,
|
||||
output_devices,
|
||||
input_devices_indices,
|
||||
output_devices_indices,
|
||||
)
|
||||
|
||||
|
||||
def set_devices(self, input_device, output_device):
|
||||
"""设置输出设备"""
|
||||
(
|
||||
input_devices,
|
||||
output_devices,
|
||||
input_device_indices,
|
||||
output_device_indices,
|
||||
) = self.get_devices()
|
||||
sd.default.device[0] = input_device_indices[
|
||||
input_devices.index(input_device)
|
||||
sd.default.device[0] = self.input_devices_indices[
|
||||
self.input_devices.index(input_device)
|
||||
]
|
||||
sd.default.device[1] = output_device_indices[
|
||||
output_devices.index(output_device)
|
||||
sd.default.device[1] = self.output_devices_indices[
|
||||
self.output_devices.index(output_device)
|
||||
]
|
||||
printt("Input device: %s:%s", str(sd.default.device[0]), input_device)
|
||||
printt("Output device: %s:%s", str(sd.default.device[1]), output_device)
|
||||
|
||||
|
||||
def get_device_samplerate(self):
|
||||
return int(sd.query_devices(device=sd.default.device[0])['default_samplerate'])
|
||||
|
||||
return int(
|
||||
sd.query_devices(device=sd.default.device[0])["default_samplerate"]
|
||||
)
|
||||
|
||||
def get_device_channels(self):
|
||||
max_input_channels = sd.query_devices(device=sd.default.device[0])[
|
||||
"max_input_channels"
|
||||
]
|
||||
max_output_channels = sd.query_devices(device=sd.default.device[1])[
|
||||
"max_output_channels"
|
||||
]
|
||||
return min(max_input_channels, max_output_channels, 2)
|
||||
|
||||
gui = GUI()
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Batch processing for vocal accompaniment separation using the UVR5 model.<br>Example of a valid folder path format: D:\\path\\to\\input\\folder (copy it from the file manager address bar).<br>The model is divided into three categories:<br>1. Preserve vocals: Choose this option for audio without harmonies. It preserves vocals better than HP5. It includes two built-in models: HP2 and HP3. HP3 may slightly leak accompaniment but preserves vocals slightly better than HP2.<br>2. Preserve main vocals only: Choose this option for audio with harmonies. It may weaken the main vocals. It includes one built-in model: HP5.<br>3. De-reverb and de-delay models (by FoxJoy):<br> (1) MDX-Net: The best choice for stereo reverb removal but cannot remove mono reverb;<br> (234) DeEcho: Removes delay effects. Aggressive mode removes more thoroughly than Normal mode. DeReverb additionally removes reverb and can remove mono reverb, but not very effectively for heavily reverberated high-frequency content.<br>De-reverb/de-delay notes:<br>1. The processing time for the DeEcho-DeReverb model is approximately twice as long as the other two DeEcho models.<br>2. The MDX-Net-Dereverb model is quite slow.<br>3. The recommended cleanest configuration is to apply MDX-Net first and then DeEcho-Aggressive.",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Enter the GPU index(es) separated by '-', e.g., 0-1-2 to use GPU 0, 1, and 2:",
|
||||
"伴奏人声分离&去混响&去回声": "Vocals/Accompaniment Separation & Reverberation Removal",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "Save name:",
|
||||
"保存的文件名, 默认空为和源文件同名": "Save file name (default: same as the source file):",
|
||||
"保存的模型名不带后缀": "Saved model name (without extension):",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "Transpose (integer, number of semitones, raise by an octave: 12, lower by an octave: -12):",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "Resample the output audio in post-processing to the final sample rate. Set to 0 for no resampling:",
|
||||
"否": "No",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "Response threshold",
|
||||
"响度因子": "loudness factor",
|
||||
"处理数据": "Process data",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "Version",
|
||||
"特征提取": "Feature extraction",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Path to the feature index file. Leave blank to use the selected result from the dropdown:",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Recommended +12 key for male to female conversion, and -12 key for female to male conversion. If the sound range goes too far and the voice is distorted, you can also adjust it to the appropriate range by yourself.",
|
||||
"目标采样率": "Target sample rate:",
|
||||
"算法延迟(ms):": "Algorithmic delays(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "Train model",
|
||||
"训练特征索引": "Train feature index",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Training complete. You can check the training logs in the console or the 'train.log' file under the experiment folder.",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "Please specify the speaker/singer ID:",
|
||||
"请选择index文件": "Please choose the .index file",
|
||||
"请选择pth文件": "Please choose the .pth file",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Select the pitch extraction algorithm ('pm': faster extraction but lower-quality speech; 'harvest': better bass but extremely slow; 'crepe': better quality but GPU intensive), 'rmvpe': best quality, and little GPU requirement",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "Select the pitch extraction algorithm: when extracting singing, you can use 'pm' to speed up. For high-quality speech with fast performance, but worse CPU usage, you can use 'dio'. 'harvest' results in better quality but is slower. 'rmvpe' has the best results and consumes less CPU/GPU",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "Sample length",
|
||||
"重载设备列表": "Reload device list",
|
||||
"音调设置": "Pitch settings",
|
||||
"音频设备(请使用同种类驱动)": "Audio device (please use the same type of driver)",
|
||||
"音频设备": "Audio device",
|
||||
"音高算法": "pitch detection algorithm",
|
||||
"额外推理时长": "Extra inference time"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Procesamiento por lotes para la separación de acompañamiento vocal utilizando el modelo UVR5.<br>Ejemplo de formato de ruta de carpeta válido: D:\\ruta\\a\\la\\carpeta\\de\\entrada (copiar desde la barra de direcciones del administrador de archivos).<br>El modelo se divide en tres categorías:<br>1. Preservar voces: Elija esta opción para audio sin armonías. Preserva las voces mejor que HP5. Incluye dos modelos incorporados: HP2 y HP3. HP3 puede filtrar ligeramente el acompañamiento pero conserva las voces un poco mejor que HP2.<br>2. Preservar solo voces principales: Elija esta opción para audio con armonías. Puede debilitar las voces principales. Incluye un modelo incorporado: HP5.<br>3. Modelos de des-reverberación y des-retardo (por FoxJoy):<br> (1) MDX-Net: La mejor opción para la eliminación de reverberación estéreo pero no puede eliminar la reverberación mono;<br> (234) DeEcho: Elimina efectos de retardo. El modo Agresivo elimina más a fondo que el modo Normal. DeReverb adicionalmente elimina la reverberación y puede eliminar la reverberación mono, pero no muy efectivamente para contenido de alta frecuencia fuertemente reverberado.<br>Notas de des-reverberación/des-retardo:<br>1. El tiempo de procesamiento para el modelo DeEcho-DeReverb es aproximadamente el doble que los otros dos modelos DeEcho.<br>2. El modelo MDX-Net-Dereverb es bastante lento.<br>3. La configuración más limpia recomendada es aplicar primero MDX-Net y luego DeEcho-Agresivo.",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Separe los números de identificación de la GPU con '-' al ingresarlos. Por ejemplo, '0-1-2' significa usar GPU 0, GPU 1 y GPU 2.",
|
||||
"伴奏人声分离&去混响&去回声": "Separación de voz acompañante & eliminación de reverberación & eco",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "Guardar nombre",
|
||||
"保存的文件名, 默认空为和源文件同名": "Nombre del archivo que se guardará, el valor predeterminado es el mismo que el nombre del archivo de origen",
|
||||
"保存的模型名不带后缀": "Nombre del modelo guardado sin extensión.",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "Cambio de tono (entero, número de semitonos, subir una octava +12 o bajar una octava -12)",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "Remuestreo posterior al proceso a la tasa de muestreo final, 0 significa no remuestrear",
|
||||
"否": "No",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "Umbral de respuesta",
|
||||
"响度因子": "factor de sonoridad",
|
||||
"处理数据": "Procesar datos",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "Versión",
|
||||
"特征提取": "Extracción de características",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Ruta del archivo de la biblioteca de características, si está vacío, se utilizará el resultado de la selección desplegable",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Tecla +12 recomendada para conversión de voz de hombre a mujer, tecla -12 para conversión de voz de mujer a hombre. Si el rango de tono es demasiado amplio y causa distorsión, ajústelo usted mismo a un rango adecuado.",
|
||||
"目标采样率": "Tasa de muestreo objetivo",
|
||||
"算法延迟(ms):": "算法延迟(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "Entrenar Modelo",
|
||||
"训练特征索引": "Índice de características",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Entrenamiento finalizado, puede ver el registro de entrenamiento en la consola o en el archivo train.log en la carpeta del experimento",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "ID del modelo",
|
||||
"请选择index文件": "Seleccione el archivo .index",
|
||||
"请选择pth文件": "Seleccione el archivo .pth",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "Seleccione el algoritmo de extracción de tono, las voces de entrada se pueden acelerar con pm, harvest tiene buenos graves pero es muy lento, crepe es bueno pero se come las GPUs",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Seleccione el algoritmo de extracción de tono, use 'pm' para acelerar la entrada de canto, 'harvest' es bueno para los graves pero extremadamente lento, 'crepe' tiene buenos resultados pero consume GPU",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "Seleccione el algoritmo de extracción de tono: la canción de entrada se puede acelerar con pm, la voz de alta calidad pero CPU pobre se puede acelerar con dio, harvest es mejor pero más lento, rmvpe es el mejor y se come ligeramente la CPU/GPU",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "Longitud de muestreo",
|
||||
"重载设备列表": "Actualizar lista de dispositivos",
|
||||
"音调设置": "Ajuste de tono",
|
||||
"音频设备(请使用同种类驱动)": "Dispositivo de audio (utilice el mismo tipo de controlador)",
|
||||
"音频设备": "Dispositivo de audio",
|
||||
"音高算法": "Algoritmo de tono",
|
||||
"额外推理时长": "Tiempo de inferencia adicional"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Traitement en lot pour la séparation de la voix et de l'accompagnement vocal à l'aide du modèle UVR5.<br>Exemple d'un format de chemin de dossier valide : D:\\chemin\\vers\\dossier\\d'entrée (copiez-le depuis la barre d'adresse du gestionnaire de fichiers).<br>Le modèle est divisé en trois catégories :<br>1. Préserver la voix : Choisissez cette option pour l'audio sans harmonies. Elle préserve la voix mieux que HP5. Il comprend deux modèles intégrés : HP2 et HP3. HP3 peut légèrement laisser passer l'accompagnement mais préserve légèrement mieux la voix que HP2.<br>2. Préserver uniquement la voix principale : Choisissez cette option pour l'audio avec harmonies. Cela peut affaiblir la voix principale. Il comprend un modèle intégré : HP5.<br>3. Modèles de suppression de la réverbération et du délai (par FoxJoy) :<br> (1) MDX-Net : Le meilleur choix pour la suppression de la réverbération stéréo, mais ne peut pas supprimer la réverbération mono.<br> (234) DeEcho : Supprime les effets de délai. Le mode Aggressive supprime plus efficacement que le mode Normal. DeReverb supprime également la réverbération et peut supprimer la réverbération mono, mais pas très efficacement pour les contenus à haute fréquence fortement réverbérés.<br>Notes sur la suppression de la réverbération et du délai :<br>1. Le temps de traitement pour le modèle DeEcho-DeReverb est environ deux fois plus long que pour les autres deux modèles DeEcho.<br>2. Le modèle MDX-Net-Dereverb est assez lent.<br>3. La configuration la plus propre recommandée est d'appliquer d'abord MDX-Net, puis DeEcho-Aggressive.",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Entrez le(s) index GPU séparé(s) par '-', par exemple, 0-1-2 pour utiliser les GPU 0, 1 et 2 :",
|
||||
"伴奏人声分离&去混响&去回声": "Séparation des voix/accompagnement et suppression de la réverbération",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "Nom de sauvegarde :",
|
||||
"保存的文件名, 默认空为和源文件同名": "Nom du fichier de sauvegarde (par défaut : identique au nom du fichier source) :",
|
||||
"保存的模型名不带后缀": "Nom du modèle enregistré (sans extension) :",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "Transposer (entier, nombre de demi-tons, monter d'une octave : 12, descendre d'une octave : -12) :",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "Rééchantillonner l'audio de sortie en post-traitement à la fréquence d'échantillonnage finale. Réglez sur 0 pour ne pas effectuer de rééchantillonnage :",
|
||||
"否": "Non",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "Seuil de réponse",
|
||||
"响度因子": "Facteur de volume sonore",
|
||||
"处理数据": "Traitement des données",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "Version",
|
||||
"特征提取": "Extraction des caractéristiques",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Chemin d'accès au fichier d'index des caractéristiques. Laisser vide pour utiliser le résultat sélectionné dans la liste déroulante :",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Il est recommandé d'utiliser la clé +12 pour la conversion homme-femme et la clé -12 pour la conversion femme-homme. Si la plage sonore est trop large et que la voix est déformée, vous pouvez également l'ajuster vous-même à la plage appropriée.",
|
||||
"目标采样率": "Taux d'échantillonnage cible :",
|
||||
"算法延迟(ms):": "Délais algorithmiques (ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "Entraîner le modèle",
|
||||
"训练特征索引": "Entraîner l'index des caractéristiques",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Entraînement terminé. Vous pouvez consulter les rapports d'entraînement dans la console ou dans le fichier 'train.log' situé dans le dossier de l'expérience.",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "Veuillez spécifier l'ID de l'orateur ou du chanteur :",
|
||||
"请选择index文件": "Veuillez sélectionner le fichier d'index",
|
||||
"请选择pth文件": "Veuillez sélectionner le fichier pth",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "Sélection de l'algorithme d'extraction de la hauteur, les voix d'entrée peuvent être accélérées avec pm, harvest a de bonnes basses mais est très lent, crepe est bon mais consomme beaucoup de ressources GPU.",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Sélectionnez l'algorithme d'extraction de la hauteur de ton (\"pm\" : extraction plus rapide mais parole de moindre qualité ; \"harvest\" : meilleure basse mais extrêmement lente ; \"crepe\" : meilleure qualité mais utilisation intensive du GPU), \"rmvpe\" : meilleure qualité et peu d'utilisation du GPU.",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "Sélection de l'algorithme d'extraction de la hauteur : la chanson d'entrée peut être traitée plus rapidement par pm, avec une voix de haute qualité mais un CPU médiocre, par dio, harvest est meilleur mais plus lent, rmvpe est le meilleur, mais consomme légèrement le CPU/GPU.",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "Longueur de l'échantillon",
|
||||
"重载设备列表": "Recharger la liste des dispositifs",
|
||||
"音调设置": "Réglages de la hauteur",
|
||||
"音频设备(请使用同种类驱动)": "Périphérique audio (veuillez utiliser le même type de pilote)",
|
||||
"音频设备": "Périphérique audio",
|
||||
"音高算法": "algorithme de détection de la hauteur",
|
||||
"额外推理时长": "Temps d'inférence supplémentaire"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Elaborazione batch per la separazione dell'accompagnamento vocale utilizzando il modello UVR5.<br>Esempio di un formato di percorso di cartella valido: D:\\path\\to\\input\\folder (copialo dalla barra degli indirizzi del file manager).<br>Il modello è suddiviso in tre categorie:<br>1. Conserva la voce: scegli questa opzione per l'audio senza armonie. <br>2. Mantieni solo la voce principale: scegli questa opzione per l'audio con armonie. <br>3. Modelli di de-riverbero e de-delay (di FoxJoy):<br> (1) MDX-Net: la scelta migliore per la rimozione del riverbero stereo ma non può rimuovere il riverbero mono;<br><br>Note di de-riverbero/de-delay:<br>1. Il tempo di elaborazione per il modello DeEcho-DeReverb è circa il doppio rispetto agli altri due modelli DeEcho.<br>2. Il modello MDX-Net-Dereverb è piuttosto lento.<br>3. La configurazione più pulita consigliata consiste nell'applicare prima MDX-Net e poi DeEcho-Aggressive.",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Inserisci gli indici GPU separati da '-', ad esempio 0-1-2 per utilizzare GPU 0, 1 e 2:",
|
||||
"伴奏人声分离&去混响&去回声": "Separazione voce/accompagnamento",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "Salva nome:",
|
||||
"保存的文件名, 默认空为和源文件同名": "Salva il nome del file (predefinito: uguale al file di origine):",
|
||||
"保存的模型名不带后缀": "Nome del modello salvato (senza estensione):",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "Trasposizione (numero intero, numero di semitoni, alza di un'ottava: 12, abbassa di un'ottava: -12):",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "Ricampiona l'audio di output in post-elaborazione alla frequenza di campionamento finale. ",
|
||||
"否": "NO",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "Soglia di risposta",
|
||||
"响度因子": "fattore di sonorità",
|
||||
"处理数据": "Processa dati",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "Versione",
|
||||
"特征提取": "Estrazione delle caratteristiche",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Percorso del file di indice delle caratteristiche. ",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Tonalità +12 consigliata per la conversione da maschio a femmina e tonalità -12 per la conversione da femmina a maschio. ",
|
||||
"目标采样率": "Frequenza di campionamento target:",
|
||||
"算法延迟(ms):": "算法延迟(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "Addestra modello",
|
||||
"训练特征索引": "Addestra indice delle caratteristiche",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Addestramento completato. ",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "Si prega di specificare l'ID del locutore/cantante:",
|
||||
"请选择index文件": "请选择index文件",
|
||||
"请选择pth文件": "请选择pth 文件",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Seleziona l'algoritmo di estrazione del tono (\"pm\": estrazione più veloce ma risultato di qualità inferiore; \"harvest\": bassi migliori ma estremamente lenti; \"crepe\": qualità migliore ma utilizzo intensivo della GPU):",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "Lunghezza del campione",
|
||||
"重载设备列表": "Ricaricare l'elenco dei dispositivi",
|
||||
"音调设置": "Impostazioni del tono",
|
||||
"音频设备(请使用同种类驱动)": "Dispositivo audio (utilizzare lo stesso tipo di driver)",
|
||||
"音频设备": "Dispositivo audio",
|
||||
"音高算法": "音高算法",
|
||||
"额外推理时长": "Tempo di inferenza extra"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "UVR5モデルを使用したボーカル伴奏の分離バッチ処理。<br>有効なフォルダーパスフォーマットの例: D:\\path\\to\\input\\folder (エクスプローラーのアドレスバーからコピーします)。<br>モデルは三つのカテゴリに分かれています:<br>1. ボーカルを保持: ハーモニーのないオーディオに対してこれを選択します。HP5よりもボーカルをより良く保持します。HP2とHP3の二つの内蔵モデルが含まれています。HP3は伴奏をわずかに漏らす可能性がありますが、HP2よりもわずかにボーカルをより良く保持します。<br>2. 主なボーカルのみを保持: ハーモニーのあるオーディオに対してこれを選択します。主なボーカルを弱める可能性があります。HP5の一つの内蔵モデルが含まれています。<br>3. ディリバーブとディレイモデル (by FoxJoy):<br> (1) MDX-Net: ステレオリバーブの除去に最適な選択肢ですが、モノリバーブは除去できません;<br> (234) DeEcho: ディレイ効果を除去します。AggressiveモードはNormalモードよりも徹底的に除去します。DeReverbはさらにリバーブを除去し、モノリバーブを除去することができますが、高周波のリバーブが強い内容に対しては非常に効果的ではありません。<br>ディリバーブ/ディレイに関する注意点:<br>1. DeEcho-DeReverbモデルの処理時間は、他の二つのDeEchoモデルの約二倍です。<br>2. MDX-Net-Dereverbモデルは非常に遅いです。<br>3. 推奨される最もクリーンな設定は、最初にMDX-Netを適用し、その後にDeEcho-Aggressiveを適用することです。",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "ハイフンで区切って使用するGPUの番号を入力します。例えば0-1-2はGPU0、GPU1、GPU2を使用します",
|
||||
"伴奏人声分离&去混响&去回声": "伴奏ボーカル分離&残響除去&エコー除去",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "保存ファイル名",
|
||||
"保存的文件名, 默认空为和源文件同名": "保存するファイル名、デフォルトでは空欄で元のファイル名と同じ名前になります",
|
||||
"保存的模型名不带后缀": "拡張子のない保存するモデル名",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "ピッチ変更(整数、半音数、上下オクターブ12-12)",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "最終的なサンプリングレートへのポストプロセッシングのリサンプリング リサンプリングしない場合は0",
|
||||
"否": "いいえ",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "反応閾値",
|
||||
"响度因子": "ラウドネス係数",
|
||||
"处理数据": "データ処理",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "バージョン",
|
||||
"特征提取": "特徴抽出",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特徴検索ライブラリへのパス 空の場合はドロップダウンで選択",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性から女性へは+12キーをお勧めします。女性から男性へは-12キーをお勧めします。音域が広すぎて音質が劣化した場合は、適切な音域に自分で調整してください。",
|
||||
"目标采样率": "目標サンプリングレート",
|
||||
"算法延迟(ms):": "算法延迟(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "モデルのトレーニング",
|
||||
"训练特征索引": "特徴インデックスのトレーニング",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "トレーニング終了時に、トレーニングログやフォルダ内のtrain.logを確認することができます",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "話者IDを指定してください",
|
||||
"请选择index文件": "indexファイルを選択してください",
|
||||
"请选择pth文件": "pthファイルを選択してください",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "ピッチ抽出アルゴリズムの選択、歌声はpmで高速化でき、harvestは低音が良いが信じられないほど遅く、crepeは良く動くがGPUを食います。",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "ピッチ抽出アルゴリズムの選択、歌声はpmで高速化でき、harvestは低音が良いが信じられないほど遅く、crepeは良く動くがGPUを喰います",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "ピッチ抽出アルゴリズムの選択:歌声はpmで高速化でき、入力した音声が高音質でCPUが貧弱な場合はdioで高速化でき、harvestの方が良いが遅く、rmvpeがベストだがCPU/GPUを若干食います。",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "サンプル長",
|
||||
"重载设备列表": "デバイスリストをリロードする",
|
||||
"音调设置": "音程設定",
|
||||
"音频设备(请使用同种类驱动)": "オーディオデバイス(同じ種類のドライバーを使用してください)",
|
||||
"音频设备": "オーディオデバイス",
|
||||
"音高算法": "ピッチアルゴリズム",
|
||||
"额外推理时长": "追加推論時間"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -0,0 +1,137 @@
|
|||
{
|
||||
">=3则使用对harvest音高识别的结果使用中值滤波,数值为滤波半径,使用可以削弱哑音": ">=3, use o filtro mediano para o resultado do reconhecimento do tom da heverst, e o valor é o raio do filtro, que pode enfraquecer o mudo.",
|
||||
"A模型权重": "Peso (w) para o modelo A:",
|
||||
"A模型路径": "Caminho para o Modelo A:",
|
||||
"B模型路径": "Caminho para o Modelo B:",
|
||||
"E:\\语音音频+标注\\米津玄师\\src": "E:\\meu-dataset",
|
||||
"F0曲线文件, 可选, 一行一个音高, 代替默认F0及升降调": "Arquivo de curva F0 (opcional). Um arremesso por linha. Substitui a modulação padrão F0 e tom:",
|
||||
"Index Rate": "Taxa do Index",
|
||||
"Onnx导出": "Exportar Onnx",
|
||||
"Onnx输出路径": "Caminho de exportação ONNX:",
|
||||
"RVC模型路径": "Caminho do Modelo RVC:",
|
||||
"ckpt处理": "processamento ckpt",
|
||||
"harvest进程数": "Número de processos harvest",
|
||||
"index文件路径不可包含中文": "O caminho do arquivo de Index não pode conter caracteres chineses",
|
||||
"pth文件路径不可包含中文": "o caminho do arquivo pth não pode conter caracteres chineses",
|
||||
"rmvpe卡号配置:以-分隔输入使用的不同进程卡号,例如0-0-1使用在卡0上跑2个进程并在卡1上跑1个进程": "Configuração do número do cartão rmvpe: Use - para separar os números dos cartões de entrada de diferentes processos. Por exemplo, 0-0-1 é usado para executar 2 processos no cartão 0 e 1 processo no cartão 1.",
|
||||
"step1: 填写实验配置. 实验数据放在logs下, 每个实验一个文件夹, 需手工输入实验名路径, 内含实验配置, 日志, 训练得到的模型文件. ": "Etapa 1: Preencha a configuração experimental. Os dados experimentais são armazenados na pasta 'logs', com cada experimento tendo uma pasta separada. Digite manualmente o caminho do nome do experimento, que contém a configuração experimental, os logs e os arquivos de modelo treinados.",
|
||||
"step1:正在处理数据": "Etapa 1: Processamento de dados",
|
||||
"step2:正在提取音高&正在提取特征": "step2:正在提取音高&正在提取特征",
|
||||
"step2a: 自动遍历训练文件夹下所有可解码成音频的文件并进行切片归一化, 在实验目录下生成2个wav文件夹; 暂时只支持单人训练. ": "Etapa 2a: Percorra automaticamente todos os arquivos na pasta de treinamento que podem ser decodificados em áudio e execute a normalização da fatia. Gera 2 pastas wav no diretório do experimento. Atualmente, apenas o treinamento de um único cantor/palestrante é suportado.",
|
||||
"step2b: 使用CPU提取音高(如果模型带音高), 使用GPU提取特征(选择卡号)": "Etapa 2b: Use a CPU para extrair o tom (se o modelo tiver tom), use a GPU para extrair recursos (selecione o índice da GPU):",
|
||||
"step3: 填写训练设置, 开始训练模型和索引": "Etapa 3: Preencha as configurações de treinamento e comece a treinar o modelo e o Index",
|
||||
"step3a:正在训练模型": "Etapa 3a: Treinamento do modelo iniciado",
|
||||
"一键训练": "Treinamento com um clique",
|
||||
"也可批量输入音频文件, 二选一, 优先读文件夹": "Você também pode inserir arquivos de áudio em lotes. Escolha uma das duas opções. É dada prioridade à leitura da pasta.",
|
||||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Processamento em lote para separação de acompanhamento vocal usando o modelo UVR5.<br>Exemplo de um formato de caminho de pasta válido: D:\\caminho\\para a pasta\\entrada\\ (copie-o da barra de endereços do gerenciador de arquivos).<br>O modelo é dividido em três categorias:<br>1. Preservar vocais: Escolha esta opção para áudio sem harmonias. Ele preserva os vocais melhor do que o HP5. Inclui dois modelos integrados: HP2 e HP3. O HP3 pode vazar ligeiramente o acompanhamento, mas preserva os vocais um pouco melhor do que o HP2.<br>2 Preservar apenas os vocais principais: Escolha esta opção para áudio com harmonias. Isso pode enfraquecer os vocais principais. Ele inclui um modelo embutido: HP5.<br>3. Modelos de de-reverb e de-delay (por FoxJoy):<br> (1) MDX-Net: A melhor escolha para remoção de reverb estéreo, mas não pode remover reverb mono;<br> (234) DeEcho: Remove efeitos de atraso. O modo agressivo remove mais completamente do que o modo normal. O DeReverb também remove reverb e pode remover reverb mono, mas não de forma muito eficaz para conteúdo de alta frequência fortemente reverberado.<br>Notas de de-reverb/de-delay:<br>1. O tempo de processamento para o modelo DeEcho-DeReverb é aproximadamente duas vezes maior que os outros dois modelos DeEcho.<br>2 O modelo MDX-Net-Dereverb é bastante lento.<br>3. A configuração mais limpa recomendada é aplicar MDX-Net primeiro e depois DeEcho-Aggressive.",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Digite o (s) índice(s) da GPU separados por '-', por exemplo, 0-1-2 para usar a GPU 0, 1 e 2:",
|
||||
"伴奏人声分离&去混响&去回声": "UVR5",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "Salvar nome",
|
||||
"保存的文件名, 默认空为和源文件同名": "Salvar nome do arquivo (padrão: igual ao arquivo de origem):",
|
||||
"保存的模型名不带后缀": "Nome do modelo salvo (sem extensão):",
|
||||
"保存频率save_every_epoch": "Faça backup a cada # de Epoch:",
|
||||
"保护清辅音和呼吸声,防止电音撕裂等artifact,拉满0.5不开启,调低加大保护力度但可能降低索引效果": "Proteja consoantes sem voz e sons respiratórios, evite artefatos como quebra de som eletrônico e desligue-o quando estiver cheio de 0,5. Diminua-o para aumentar a proteção, mas pode reduzir o efeito de indexação:",
|
||||
"修改": "Editar",
|
||||
"修改模型信息(仅支持weights文件夹下提取的小模型文件)": "Modificar informações do modelo (suportado apenas para arquivos de modelo pequenos extraídos da pasta 'weights')",
|
||||
"停止音频转换": "Conversão de áudio",
|
||||
"全流程结束!": "Todos os processos foram concluídos!",
|
||||
"刷新音色列表和索引路径": "Atualizar lista de voz e caminho do Index",
|
||||
"加载模型": "Modelo",
|
||||
"加载预训练底模D路径": "Carregue o caminho D do modelo base pré-treinado:",
|
||||
"加载预训练底模G路径": "Carregue o caminho G do modelo base pré-treinado:",
|
||||
"单次推理": "Único",
|
||||
"卸载音色省显存": "Descarregue a voz para liberar a memória da GPU:",
|
||||
"变调(整数, 半音数量, 升八度12降八度-12)": "Mude o tom aqui. Se a voz for do mesmo sexo, não é necessario alterar (12 caso seja Masculino para feminino, -12 caso seja ao contrário).",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "Reamostragem pós-processamento para a taxa de amostragem final, 0 significa sem reamostragem:",
|
||||
"否": "Não",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "Limiar de resposta",
|
||||
"响度因子": "Fator de volume",
|
||||
"处理数据": "Processar o Conjunto de Dados",
|
||||
"导出Onnx模型": "Exportar Modelo Onnx",
|
||||
"导出文件格式": "Qual formato de arquivo você prefere?",
|
||||
"常见问题解答": "FAQ (Perguntas frequentes)",
|
||||
"常规设置": "Configurações gerais",
|
||||
"开始音频转换": "Iniciar conversão de áudio",
|
||||
"很遗憾您这没有能用的显卡来支持您训练": "Infelizmente, não há GPU compatível disponível para apoiar o seu treinamento.",
|
||||
"性能设置": "Configurações de desempenho.",
|
||||
"总训练轮数total_epoch": "Número total de ciclos(epoch) de treino (se escolher um valor alto demais, o seu modelo parecerá terrivelmente sobretreinado):",
|
||||
"批量推理": "Conversão em Lote",
|
||||
"批量转换, 输入待转换音频文件夹, 或上传多个音频文件, 在指定文件夹(默认opt)下输出转换的音频. ": "Conversão em Massa.",
|
||||
"指定输出主人声文件夹": "Especifique a pasta de saída para vocais:",
|
||||
"指定输出文件夹": "Especifique a pasta de saída:",
|
||||
"指定输出非主人声文件夹": "Informar a pasta de saída para acompanhamento:",
|
||||
"推理时间(ms):": "Tempo de inferência (ms):",
|
||||
"推理音色": "Escolha o seu Modelo:",
|
||||
"提取": "Extrato",
|
||||
"提取音高和处理数据使用的CPU进程数": "Número de processos de CPU usados para extração de tom e processamento de dados:",
|
||||
"是": "Sim",
|
||||
"是否仅保存最新的ckpt文件以节省硬盘空间": "Só deve salvar apenas o arquivo ckpt mais recente para economizar espaço em disco:",
|
||||
"是否在每次保存时间点将最终小模型保存至weights文件夹": "Salve um pequeno modelo final na pasta 'weights' em cada ponto de salvamento:",
|
||||
"是否缓存所有训练集至显存. 10min以下小数据可缓存以加速训练, 大数据缓存会炸显存也加不了多少速": "Se deve armazenar em cache todos os conjuntos de treinamento na memória de vídeo. Pequenos dados com menos de 10 minutos podem ser armazenados em cache para acelerar o treinamento, e um cache de dados grande irá explodir a memória de vídeo e não aumentar muito a velocidade:",
|
||||
"显卡信息": "Informações da GPU",
|
||||
"本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责. <br>如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录<b>LICENSE</b>.": "<center>The Mangio-RVC 💻 | Tradução por Krisp e Rafael Godoy Ebert | AI HUB BRASIL<br> Este software é de código aberto sob a licença MIT. O autor não tem qualquer controle sobre o software. Aqueles que usam o software e divulgam os sons exportados pelo software são totalmente responsáveis. <br>Se você não concorda com este termo, você não pode usar ou citar nenhum código e arquivo no pacote de software. Para obter detalhes, consulte o diretório raiz <b>O acordo a ser seguido para uso <a href='https://raw.githubusercontent.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/main/LICENSE' target='_blank'>LICENSE</a></b></center>",
|
||||
"查看": "Visualizar",
|
||||
"查看模型信息(仅支持weights文件夹下提取的小模型文件)": "Exibir informações do modelo (suportado apenas para arquivos de modelo pequenos extraídos da pasta 'weights')",
|
||||
"检索特征占比": "Taxa de recurso de recuperação:",
|
||||
"模型": "Modelo",
|
||||
"模型推理": "Inference",
|
||||
"模型提取(输入logs文件夹下大文件模型路径),适用于训一半不想训了模型没有自动提取保存小文件模型,或者想测试中间模型的情况": "Extração do modelo (insira o caminho do modelo de arquivo grande na pasta 'logs'). Isso é útil se você quiser interromper o treinamento no meio do caminho e extrair e salvar manualmente um arquivo de modelo pequeno, ou se quiser testar um modelo intermediário:",
|
||||
"模型是否带音高指导": "Se o modelo tem orientação de tom:",
|
||||
"模型是否带音高指导(唱歌一定要, 语音可以不要)": "Se o modelo tem orientação de tom (necessário para cantar, opcional para fala):",
|
||||
"模型是否带音高指导,1是0否": "Se o modelo tem orientação de passo (1: sim, 0: não):",
|
||||
"模型版本型号": "Versão:",
|
||||
"模型融合, 可用于测试音色融合": "A fusão modelo, pode ser usada para testar a fusão do timbre",
|
||||
"模型路径": "Caminho para o Modelo:",
|
||||
"每张显卡的batch_size": "Batch Size (DEIXE COMO ESTÁ a menos que saiba o que está fazendo, no Colab pode deixar até 20!):",
|
||||
"淡入淡出长度": "Comprimento de desvanecimento",
|
||||
"版本": "Versão",
|
||||
"特征提取": "Extrair Tom",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Caminho para o arquivo de Index. Deixe em branco para usar o resultado selecionado no menu debaixo:",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Recomendado +12 chave para conversão de homem para mulher e -12 chave para conversão de mulher para homem. Se a faixa de som for muito longe e a voz estiver distorcida, você também pode ajustá-la à faixa apropriada por conta própria.",
|
||||
"目标采样率": "Taxa de amostragem:",
|
||||
"算法延迟(ms):": "Atrasos algorítmicos (ms):",
|
||||
"自动检测index路径,下拉式选择(dropdown)": "Detecte automaticamente o caminho do Index e selecione no menu suspenso:",
|
||||
"融合": "Fusão",
|
||||
"要改的模型信息": "Informações do modelo a ser modificado:",
|
||||
"要置入的模型信息": "Informações do modelo a ser colocado:",
|
||||
"训练": "Treinar",
|
||||
"训练模型": "Treinar Modelo",
|
||||
"训练特征索引": "Treinar Index",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Após o término do treinamento, você pode verificar o log de treinamento do console ou train.log na pasta de experimentos",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "Especifique o ID do locutor/cantor:",
|
||||
"请选择index文件": "Selecione o arquivo de Index",
|
||||
"请选择pth文件": "Selecione o arquivo pth",
|
||||
"请选择说话人id": "Selecione Palestrantes/Cantores ID:",
|
||||
"转换": "Converter",
|
||||
"输入实验名": "Nome da voz:",
|
||||
"输入待处理音频文件夹路径": "Caminho da pasta de áudio a ser processada:",
|
||||
"输入待处理音频文件夹路径(去文件管理器地址栏拷就行了)": "Caminho da pasta de áudio a ser processada (copie-o da barra de endereços do gerenciador de arquivos):",
|
||||
"输入待处理音频文件路径(默认是正确格式示例)": "Caminho para o seu conjunto de dados (áudios, não zipado):",
|
||||
"输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络": "O envelope de volume da fonte de entrada substitui a taxa de fusão do envelope de volume de saída, quanto mais próximo de 1, mais o envelope de saída é usado:",
|
||||
"输入监听": "Monitoramento de entrada",
|
||||
"输入训练文件夹路径": "Caminho da pasta de treinamento:",
|
||||
"输入设备": "Dispositivo de entrada",
|
||||
"输入降噪": "Redução de ruído de entrada",
|
||||
"输出信息": "Informação de saída",
|
||||
"输出变声": "Mudança de voz de saída",
|
||||
"输出设备": "Dispositivo de saída",
|
||||
"输出降噪": "Redução de ruído de saída",
|
||||
"输出音频(右下角三个点,点了可以下载)": "Exportar áudio (clique nos três pontos no canto inferior direito para baixar)",
|
||||
"选择.index文件": "Selecione o Index",
|
||||
"选择.pth文件": "Selecione o Arquivo",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Selecione o algoritmo de extração de tom \n'pm': extração mais rápida, mas discurso de qualidade inferior; \n'harvest': graves melhores, mas extremamente lentos; \n'harvest': melhor qualidade, mas extração mais lenta); 'crepe': melhor qualidade, mas intensivo em GPU; 'magio-crepe': melhor opção; 'RMVPE': um modelo robusto para estimativa de afinação vocal em música polifônica;",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "Selecione o algoritmo de extração de tom \n'pm': extração mais rápida, mas discurso de qualidade inferior; \n'harvest': graves melhores, mas extremamente lentos; \n'crepe': melhor qualidade (mas intensivo em GPU);\n rmvpe tem o melhor efeito e consome menos CPU/GPU.",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "Comprimento da Amostra",
|
||||
"重载设备列表": "Recarregar lista de dispositivos",
|
||||
"音调设置": "Configurações de tom",
|
||||
"音频设备": "音频设备",
|
||||
"音高算法": "Algoritmo de detecção de pitch",
|
||||
"额外推理时长": "Tempo extra de inferência"
|
||||
}
|
||||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Пакетная обработка для разделения вокального сопровождения с использованием модели UVR5.<br>Пример допустимого формата пути к папке: D:\\path\\to\\input\\folder<br> Модель разделена на три категории:<br>1. Сохранить вокал: выберите этот вариант для звука без гармоний. Он сохраняет вокал лучше, чем HP5. Он включает в себя две встроенные модели: HP2 и HP3. HP3 может немного пропускать инструментал, но сохраняет вокал немного лучше, чем HP2.<br>2. Сохранить только основной вокал: выберите этот вариант для звука с гармониями. Это может ослабить основной вокал. Он включает одну встроенную модель: HP5.<br>3. Модели удаления реверберации и задержки (от FoxJoy):<br> (1) MDX-Net: лучший выбор для удаления стереореверберации, но он не может удалить монореверберацию;<br> (234) DeEcho: удаляет эффекты задержки. Агрессивный режим удаляет более тщательно, чем Нормальный режим. DeReverb дополнительно удаляет реверберацию и может удалять монореверберацию, но не очень эффективно для сильно реверберированного высокочастотного контента.<br>Примечания по удалению реверберации/задержки:<br>1. Время обработки для модели DeEcho-DeReverb примерно в два раза больше, чем для двух других моделей DeEcho.<br>2. Модель MDX-Net-Dereverb довольно медленная.<br>3. Рекомендуемая самая чистая конфигурация — сначала применить MDX-Net, а затем DeEcho-Aggressive.",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "Введите, какие(-ую) GPU(-у) хотите использовать через '-', например 0-1-2, чтобы использовать GPU с номерами 0, 1 и 2:",
|
||||
"伴奏人声分离&去混响&去回声": "Разделение вокала/аккомпанемента и удаление эхо",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "Имя файла для сохранения:",
|
||||
"保存的文件名, 默认空为和源文件同名": "Название сохранённого файла (по умолчанию: такое же, как и у входного):",
|
||||
"保存的模型名不带后缀": "Имя файла модели для сохранения (без расширения):",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "Изменить высоту голоса (укажите количество полутонов; чтобы поднять голос на октаву, выберите 12, понизить на октаву — -12):",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "Изменить частоту дискретизации в выходном файле на финальную. Поставьте 0, чтобы ничего не изменялось:",
|
||||
"否": "Нет",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "Порог ответа",
|
||||
"响度因子": "коэффициент громкости",
|
||||
"处理数据": "Обработать данные",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "Версия архитектуры модели:",
|
||||
"特征提取": "Извлечь черты",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Путь к файлу индекса черт. Оставьте пустым, чтобы использовать выбранный вариант из списка ниже:",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Рекомендуется выбрать +12 для конвертирования мужского голоса в женский и -12 для конвертирования женского в мужской. Если диапазон голоса слишком велик, и голос искажается, можно выбрать значение на свой вкус.",
|
||||
"目标采样率": "Частота дискретизации аудио:",
|
||||
"算法延迟(ms):": "算法延迟(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "Обучить модель",
|
||||
"训练特征索引": "Обучить индекс черт",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Обучение модели завершено. Журнал обучения можно просмотреть в консоли или в файле 'train.log' в папке с моделью.",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "Номер говорящего/поющего:",
|
||||
"请选择index文件": "Пожалуйста, выберите файл индекса",
|
||||
"请选择pth文件": "Пожалуйста, выберите файл pth",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Выберите алгоритм оценки высоты голоса ('pm': работает быстро, но даёт низкое качество речи; 'harvest': басы лучше, но работает очень медленно; 'crepe': лучшее качество, но сильно нагружает GPU; 'rmvpe': лучшее качество и минимальная нагрузка на GPU):",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "Длина сэмпла",
|
||||
"重载设备列表": "Обновить список устройств",
|
||||
"音调设置": "Настройка высоты звука",
|
||||
"音频设备(请使用同种类驱动)": "Аудиоустройство (пожалуйста, используйте такой же тип драйвера)",
|
||||
"音频设备": "Аудиоустройство",
|
||||
"音高算法": "Алгоритм оценки высоты звука",
|
||||
"额外推理时长": "Доп. время переработки"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "Batch işleme kullanarak vokal eşlik ayrımı için UVR5 modeli kullanılır.<br>Geçerli bir klasör yol formatı örneği: D:\\path\\to\\input\\folder (dosya yöneticisi adres çubuğundan kopyalanır).<br>Model üç kategoriye ayrılır:<br>1. Vokalleri koru: Bu seçeneği, harmoni içermeyen sesler için kullanın. HP5'ten daha iyi bir şekilde vokalleri korur. İki dahili model içerir: HP2 ve HP3. HP3, eşlik sesini hafifçe sızdırabilir, ancak vokalleri HP2'den biraz daha iyi korur.<br>2. Sadece ana vokalleri koru: Bu seçeneği, harmoni içeren sesler için kullanın. Ana vokalleri zayıflatabilir. Bir dahili model içerir: HP5.<br>3. Reverb ve gecikme modelleri (FoxJoy tarafından):<br> (1) MDX-Net: Stereo reverb'i kaldırmak için en iyi seçenek, ancak mono reverb'i kaldıramaz;<br> (234) DeEcho: Gecikme efektlerini kaldırır. Agresif mod, Normal moda göre daha kapsamlı bir şekilde kaldırma yapar. DeReverb ayrıca reverb'i kaldırır ve mono reverb'i kaldırabilir, ancak yoğun yankılı yüksek frekanslı içerikler için çok etkili değildir.<br>Reverb/gecikme notları:<br>1. DeEcho-DeReverb modelinin işleme süresi diğer iki DeEcho modeline göre yaklaşık olarak iki kat daha uzundur.<br>2. MDX-Net-Dereverb modeli oldukça yavaştır.<br>3. Tavsiye edilen en temiz yapılandırma önce MDX-Net'i uygulamak ve ardından DeEcho-Aggressive uygulamaktır.",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "GPU indekslerini '-' ile ayırarak girin, örneğin 0-1-2, GPU 0, 1 ve 2'yi kullanmak için:",
|
||||
"伴奏人声分离&去混响&去回声": "Vokal/Müzik Ayrıştırma ve Yankı Giderme",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "Kaydetme Adı:",
|
||||
"保存的文件名, 默认空为和源文件同名": "Kaydedilecek dosya adı (varsayılan: kaynak dosya ile aynı):",
|
||||
"保存的模型名不带后缀": "Kaydedilecek model adı (uzantı olmadan):",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "Transpoze et (tamsayı, yarıton sayısıyla; bir oktav yükseltmek için: 12, bir oktav düşürmek için: -12):",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "Son işleme aşamasında çıktı sesini son örnekleme hızına yeniden örnekle. 0 değeri için yeniden örnekleme yapılmaz:",
|
||||
"否": "Hayır",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "Tepki eşiği",
|
||||
"响度因子": "ses yüksekliği faktörü",
|
||||
"处理数据": "Verileri işle",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "Sürüm",
|
||||
"特征提取": "Özellik çıkartma",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "Özellik indeksi dosyasının yolunu belirtin. Seçilen sonucu kullanmak için boş bırakın veya açılır menüden seçim yapın.",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "Erkekten kadına çevirmek için +12 tuş önerilir, kadından erkeğe çevirmek için ise -12 tuş önerilir. Eğer ses aralığı çok fazla genişler ve ses bozulursa, isteğe bağlı olarak uygun aralığa kendiniz de ayarlayabilirsiniz.",
|
||||
"目标采样率": "Hedef örnekleme oranı:",
|
||||
"算法延迟(ms):": "算法延迟(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "Modeli Eğit",
|
||||
"训练特征索引": "Özellik Dizinini Eğit",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "Eğitim tamamlandı. Eğitim günlüklerini konsolda veya deney klasörü altındaki train.log dosyasında kontrol edebilirsiniz.",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "Lütfen konuşmacı/sanatçı no belirtin:",
|
||||
"请选择index文件": "Lütfen .index dosyası seçin",
|
||||
"请选择pth文件": "Lütfen .pth dosyası seçin",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "Pitch algoritmasını seçin ('pm': daha hızlı çıkarır ancak daha düşük kaliteli konuşma; 'harvest': daha iyi konuşma sesi ancak son derece yavaş; 'crepe': daha da iyi kalite ancak GPU yoğunluğu gerektirir):",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "Örnekleme uzunluğu",
|
||||
"重载设备列表": "Cihaz listesini yeniden yükle",
|
||||
"音调设置": "Pitch ayarları",
|
||||
"音频设备(请使用同种类驱动)": "Ses cihazı (aynı tür sürücüyü kullanın)",
|
||||
"音频设备": "Ses cihazı",
|
||||
"音高算法": "音高算法",
|
||||
"额外推理时长": "Ekstra çıkartma süresi"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2",
|
||||
"伴奏人声分离&去混响&去回声": "伴奏人声分离&去混响&去回声",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "保存名",
|
||||
"保存的文件名, 默认空为和源文件同名": "保存的文件名, 默认空为和源文件同名",
|
||||
"保存的模型名不带后缀": "保存的模型名不带后缀",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "变调(整数, 半音数量, 升八度12降八度-12)",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "后处理重采样至最终采样率,0为不进行重采样",
|
||||
"否": "否",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "响应阈值",
|
||||
"响度因子": "响度因子",
|
||||
"处理数据": "处理数据",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "版本",
|
||||
"特征提取": "特征提取",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特征检索库文件路径,为空则使用下拉的选择结果",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ",
|
||||
"目标采样率": "目标采样率",
|
||||
"算法延迟(ms):": "算法延迟(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "训练模型",
|
||||
"训练特征索引": "训练特征索引",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "请指定说话人id",
|
||||
"请选择index文件": "请选择index文件",
|
||||
"请选择pth文件": "请选择pth文件",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "采样长度",
|
||||
"重载设备列表": "重载设备列表",
|
||||
"音调设置": "音调设置",
|
||||
"音频设备(请使用同种类驱动)": "音频设备(请使用同种类驱动)",
|
||||
"音频设备": "音频设备",
|
||||
"音高算法": "音高算法",
|
||||
"额外推理时长": "额外推理时长"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "使用UVR5模型進行人聲伴奏分離的批次處理。<br>有效資料夾路徑格式的例子:D:\\path\\to\\input\\folder(從檔案管理員地址欄複製)。<br>模型分為三類:<br>1. 保留人聲:選擇這個選項適用於沒有和聲的音訊。它比HP5更好地保留了人聲。它包括兩個內建模型:HP2和HP3。HP3可能輕微漏出伴奏,但比HP2更好地保留了人聲;<br>2. 僅保留主人聲:選擇這個選項適用於有和聲的音訊。它可能會削弱主人聲。它包括一個內建模型:HP5。<br>3. 消除混響和延遲模型(由FoxJoy提供):<br> (1) MDX-Net:對於立體聲混響的移除是最好的選擇,但不能移除單聲道混響;<br> (234) DeEcho:移除延遲效果。Aggressive模式比Normal模式移除得更徹底。DeReverb另外移除混響,可以移除單聲道混響,但對於高頻重的板式混響移除不乾淨。<br>消除混響/延遲注意事項:<br>1. DeEcho-DeReverb模型的處理時間是其他兩個DeEcho模型的近兩倍;<br>2. MDX-Net-Dereverb模型相當慢;<br>3. 個人推薦的最乾淨配置是先使用MDX-Net,然後使用DeEcho-Aggressive。",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "以-分隔輸入使用的卡號, 例如 0-1-2 使用卡0和卡1和卡2",
|
||||
"伴奏人声分离&去混响&去回声": "伴奏人聲分離&去混響&去回聲",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "儲存名",
|
||||
"保存的文件名, 默认空为和源文件同名": "儲存的檔案名,預設空為與來源檔案同名",
|
||||
"保存的模型名不带后缀": "儲存的模型名不帶副檔名",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "變調(整數、半音數量、升八度12降八度-12)",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "後處理重採樣至最終採樣率,0為不進行重採樣",
|
||||
"否": "否",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "響應閾值",
|
||||
"响度因子": "響度因子",
|
||||
"处理数据": "處理資料",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "版本",
|
||||
"特征提取": "特徵提取",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
|
||||
"目标采样率": "目標取樣率",
|
||||
"算法延迟(ms):": "算法延迟(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "訓練模型",
|
||||
"训练特征索引": "訓練特徵索引",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "請指定說話人id",
|
||||
"请选择index文件": "请选择index文件",
|
||||
"请选择pth文件": "请选择pth文件",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "選擇音高提取演算法,輸入歌聲可用pm提速,harvest低音好但巨慢無比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "取樣長度",
|
||||
"重载设备列表": "重載設備列表",
|
||||
"音调设置": "音調設定",
|
||||
"音频设备(请使用同种类驱动)": "音訊設備 (請使用同種類驅動)",
|
||||
"音频设备": "音訊設備",
|
||||
"音高算法": "音高演算法",
|
||||
"额外推理时长": "額外推理時長"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "使用UVR5模型進行人聲伴奏分離的批次處理。<br>有效資料夾路徑格式的例子:D:\\path\\to\\input\\folder(從檔案管理員地址欄複製)。<br>模型分為三類:<br>1. 保留人聲:選擇這個選項適用於沒有和聲的音訊。它比HP5更好地保留了人聲。它包括兩個內建模型:HP2和HP3。HP3可能輕微漏出伴奏,但比HP2更好地保留了人聲;<br>2. 僅保留主人聲:選擇這個選項適用於有和聲的音訊。它可能會削弱主人聲。它包括一個內建模型:HP5。<br>3. 消除混響和延遲模型(由FoxJoy提供):<br> (1) MDX-Net:對於立體聲混響的移除是最好的選擇,但不能移除單聲道混響;<br> (234) DeEcho:移除延遲效果。Aggressive模式比Normal模式移除得更徹底。DeReverb另外移除混響,可以移除單聲道混響,但對於高頻重的板式混響移除不乾淨。<br>消除混響/延遲注意事項:<br>1. DeEcho-DeReverb模型的處理時間是其他兩個DeEcho模型的近兩倍;<br>2. MDX-Net-Dereverb模型相當慢;<br>3. 個人推薦的最乾淨配置是先使用MDX-Net,然後使用DeEcho-Aggressive。",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "以-分隔輸入使用的卡號, 例如 0-1-2 使用卡0和卡1和卡2",
|
||||
"伴奏人声分离&去混响&去回声": "伴奏人聲分離&去混響&去回聲",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "儲存名",
|
||||
"保存的文件名, 默认空为和源文件同名": "儲存的檔案名,預設空為與來源檔案同名",
|
||||
"保存的模型名不带后缀": "儲存的模型名不帶副檔名",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "變調(整數、半音數量、升八度12降八度-12)",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "後處理重採樣至最終採樣率,0為不進行重採樣",
|
||||
"否": "否",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "響應閾值",
|
||||
"响度因子": "響度因子",
|
||||
"处理数据": "處理資料",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "版本",
|
||||
"特征提取": "特徵提取",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
|
||||
"目标采样率": "目標取樣率",
|
||||
"算法延迟(ms):": "算法延迟(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "訓練模型",
|
||||
"训练特征索引": "訓練特徵索引",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "請指定說話人id",
|
||||
"请选择index文件": "请选择index文件",
|
||||
"请选择pth文件": "请选择pth文件",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "選擇音高提取演算法,輸入歌聲可用pm提速,harvest低音好但巨慢無比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "取樣長度",
|
||||
"重载设备列表": "重載設備列表",
|
||||
"音调设置": "音調設定",
|
||||
"音频设备(请使用同种类驱动)": "音訊設備 (請使用同種類驅動)",
|
||||
"音频设备": "音訊設備",
|
||||
"音高算法": "音高演算法",
|
||||
"额外推理时长": "額外推理時長"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -26,6 +26,8 @@
|
|||
"人声伴奏分离批量处理, 使用UVR5模型。 <br>合格的文件夹路径格式举例: E:\\codes\\py39\\vits_vc_gpu\\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。 <br>模型分为三类: <br>1、保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点; <br>2、仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型; <br> 3、去混响、去延迟模型(by FoxJoy):<br> (1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;<br> (234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。<br>去混响/去延迟,附:<br>1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;<br>2、MDX-Net-Dereverb模型挺慢的;<br>3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。": "使用UVR5模型進行人聲伴奏分離的批次處理。<br>有效資料夾路徑格式的例子:D:\\path\\to\\input\\folder(從檔案管理員地址欄複製)。<br>模型分為三類:<br>1. 保留人聲:選擇這個選項適用於沒有和聲的音訊。它比HP5更好地保留了人聲。它包括兩個內建模型:HP2和HP3。HP3可能輕微漏出伴奏,但比HP2更好地保留了人聲;<br>2. 僅保留主人聲:選擇這個選項適用於有和聲的音訊。它可能會削弱主人聲。它包括一個內建模型:HP5。<br>3. 消除混響和延遲模型(由FoxJoy提供):<br> (1) MDX-Net:對於立體聲混響的移除是最好的選擇,但不能移除單聲道混響;<br> (234) DeEcho:移除延遲效果。Aggressive模式比Normal模式移除得更徹底。DeReverb另外移除混響,可以移除單聲道混響,但對於高頻重的板式混響移除不乾淨。<br>消除混響/延遲注意事項:<br>1. DeEcho-DeReverb模型的處理時間是其他兩個DeEcho模型的近兩倍;<br>2. MDX-Net-Dereverb模型相當慢;<br>3. 個人推薦的最乾淨配置是先使用MDX-Net,然後使用DeEcho-Aggressive。",
|
||||
"以-分隔输入使用的卡号, 例如 0-1-2 使用卡0和卡1和卡2": "以-分隔輸入使用的卡號, 例如 0-1-2 使用卡0和卡1和卡2",
|
||||
"伴奏人声分离&去混响&去回声": "伴奏人聲分離&去混響&去回聲",
|
||||
"使用模型采样率": "使用模型采样率",
|
||||
"使用设备采样率": "使用设备采样率",
|
||||
"保存名": "儲存名",
|
||||
"保存的文件名, 默认空为和源文件同名": "儲存的檔案名,預設空為與來源檔案同名",
|
||||
"保存的模型名不带后缀": "儲存的模型名不帶副檔名",
|
||||
|
|
@ -44,6 +46,7 @@
|
|||
"变调(整数, 半音数量, 升八度12降八度-12)": "變調(整數、半音數量、升八度12降八度-12)",
|
||||
"后处理重采样至最终采样率,0为不进行重采样": "後處理重採樣至最終採樣率,0為不進行重採樣",
|
||||
"否": "否",
|
||||
"启用相位声码器": "启用相位声码器",
|
||||
"响应阈值": "響應閾值",
|
||||
"响度因子": "響度因子",
|
||||
"处理数据": "處理資料",
|
||||
|
|
@ -87,6 +90,7 @@
|
|||
"版本": "版本",
|
||||
"特征提取": "特徵提取",
|
||||
"特征检索库文件路径,为空则使用下拉的选择结果": "特徵檢索庫檔路徑,為空則使用下拉的選擇結果",
|
||||
"独占 WASAPI 设备": "独占 WASAPI 设备",
|
||||
"男转女推荐+12key, 女转男推荐-12key, 如果音域爆炸导致音色失真也可以自己调整到合适音域. ": "男性轉女性推薦+12key,女性轉男性推薦-12key,如果音域爆炸導致音色失真也可以自己調整到合適音域。",
|
||||
"目标采样率": "目標取樣率",
|
||||
"算法延迟(ms):": "算法延迟(ms):",
|
||||
|
|
@ -98,6 +102,7 @@
|
|||
"训练模型": "訓練模型",
|
||||
"训练特征索引": "訓練特徵索引",
|
||||
"训练结束, 您可查看控制台训练日志或实验文件夹下的train.log": "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log",
|
||||
"设备类型": "设备类型",
|
||||
"请指定说话人id": "請指定說話人id",
|
||||
"请选择index文件": "请选择index文件",
|
||||
"请选择pth文件": "请选择pth文件",
|
||||
|
|
@ -122,10 +127,11 @@
|
|||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU": "选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU",
|
||||
"选择音高提取算法,输入歌声可用pm提速,harvest低音好但巨慢无比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU": "選擇音高提取演算法,輸入歌聲可用pm提速,harvest低音好但巨慢無比,crepe效果好但吃GPU,rmvpe效果最好且微吃GPU",
|
||||
"选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU": "选择音高提取算法:输入歌声可用pm提速,高质量语音但CPU差可用dio提速,harvest质量更好但慢,rmvpe效果最好且微吃CPU/GPU",
|
||||
"采样率:": "采样率:",
|
||||
"采样长度": "取樣長度",
|
||||
"重载设备列表": "重載設備列表",
|
||||
"音调设置": "音調設定",
|
||||
"音频设备(请使用同种类驱动)": "音訊設備 (請使用同種類驅動)",
|
||||
"音频设备": "音訊設備",
|
||||
"音高算法": "音高演算法",
|
||||
"额外推理时长": "額外推理時長"
|
||||
}
|
||||
|
|
|
|||
18
infer-web.py
18
infer-web.py
|
|
@ -207,7 +207,6 @@ def preprocess_dataset(trainset_dir, exp_dir, sr, n_p):
|
|||
os.makedirs("%s/logs/%s" % (now_dir, exp_dir), exist_ok=True)
|
||||
f = open("%s/logs/%s/preprocess.log" % (now_dir, exp_dir), "w")
|
||||
f.close()
|
||||
per = 3.0 if config.is_half else 3.7
|
||||
cmd = '"%s" infer/modules/train/preprocess.py "%s" %s %s "%s/logs/%s" %s %.1f' % (
|
||||
config.python_cmd,
|
||||
trainset_dir,
|
||||
|
|
@ -216,9 +215,9 @@ def preprocess_dataset(trainset_dir, exp_dir, sr, n_p):
|
|||
now_dir,
|
||||
exp_dir,
|
||||
config.noparallel,
|
||||
per,
|
||||
config.preprocess_per,
|
||||
)
|
||||
logger.info(cmd)
|
||||
logger.info("Execute: " + cmd)
|
||||
# , stdin=PIPE, stdout=PIPE,stderr=PIPE,cwd=now_dir
|
||||
p = Popen(cmd, shell=True)
|
||||
# 煞笔gr, popen read都非得全跑完了再一次性读取, 不用gr就正常读一句输出一句;只能额外弄出一个文本流定时读
|
||||
|
|
@ -260,7 +259,7 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||
f0method,
|
||||
)
|
||||
)
|
||||
logger.info(cmd)
|
||||
logger.info("Execute: " + cmd)
|
||||
p = Popen(
|
||||
cmd, shell=True, cwd=now_dir
|
||||
) # , stdin=PIPE, stdout=PIPE,stderr=PIPE
|
||||
|
|
@ -291,7 +290,7 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||
config.is_half,
|
||||
)
|
||||
)
|
||||
logger.info(cmd)
|
||||
logger.info("Execute: " + cmd)
|
||||
p = Popen(
|
||||
cmd, shell=True, cwd=now_dir
|
||||
) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
|
||||
|
|
@ -314,7 +313,7 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||
exp_dir,
|
||||
)
|
||||
)
|
||||
logger.info(cmd)
|
||||
logger.info("Execute: " + cmd)
|
||||
p = Popen(
|
||||
cmd, shell=True, cwd=now_dir
|
||||
) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
|
||||
|
|
@ -344,7 +343,7 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||
ps = []
|
||||
for idx, n_g in enumerate(gpus):
|
||||
cmd = (
|
||||
'"%s" infer/modules/train/extract_feature_print.py %s %s %s %s "%s/logs/%s" %s'
|
||||
'"%s" infer/modules/train/extract_feature_print.py %s %s %s %s "%s/logs/%s" %s %s'
|
||||
% (
|
||||
config.python_cmd,
|
||||
config.device,
|
||||
|
|
@ -354,9 +353,10 @@ def extract_f0_feature(gpus, n_p, f0method, if_f0, exp_dir, version19, gpus_rmvp
|
|||
now_dir,
|
||||
exp_dir,
|
||||
version19,
|
||||
config.is_half,
|
||||
)
|
||||
)
|
||||
logger.info(cmd)
|
||||
logger.info("Execute: " + cmd)
|
||||
p = Popen(
|
||||
cmd, shell=True, cwd=now_dir
|
||||
) # , shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE, cwd=now_dir
|
||||
|
|
@ -589,7 +589,7 @@ def click_train(
|
|||
version19,
|
||||
)
|
||||
)
|
||||
logger.info(cmd)
|
||||
logger.info("Execute: " + cmd)
|
||||
p = Popen(cmd, shell=True, cwd=now_dir)
|
||||
p.wait()
|
||||
return "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log"
|
||||
|
|
|
|||
|
|
@ -795,9 +795,9 @@ class SynthesizerTrnMs256NSFsid(nn.Module):
|
|||
assert isinstance(return_length, torch.Tensor)
|
||||
head = int(skip_head.item())
|
||||
length = int(return_length.item())
|
||||
z_p = z_p[:, :, head: head + length]
|
||||
x_mask = x_mask[:, :, head: head + length]
|
||||
nsff0 = nsff0[:, head: head + length]
|
||||
z_p = z_p[:, :, head : head + length]
|
||||
x_mask = x_mask[:, :, head : head + length]
|
||||
nsff0 = nsff0[:, head : head + length]
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, nsff0, g=g)
|
||||
return o, x_mask, (z, z_p, m_p, logs_p)
|
||||
|
|
@ -957,9 +957,9 @@ class SynthesizerTrnMs768NSFsid(nn.Module):
|
|||
assert isinstance(return_length, torch.Tensor)
|
||||
head = int(skip_head.item())
|
||||
length = int(return_length.item())
|
||||
z_p = z_p[:, :, head: head + length]
|
||||
x_mask = x_mask[:, :, head: head + length]
|
||||
nsff0 = nsff0[:, head: head + length]
|
||||
z_p = z_p[:, :, head : head + length]
|
||||
x_mask = x_mask[:, :, head : head + length]
|
||||
nsff0 = nsff0[:, head : head + length]
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, nsff0, g=g)
|
||||
return o, x_mask, (z, z_p, m_p, logs_p)
|
||||
|
|
@ -1108,8 +1108,8 @@ class SynthesizerTrnMs256NSFsid_nono(nn.Module):
|
|||
assert isinstance(return_length, torch.Tensor)
|
||||
head = int(skip_head.item())
|
||||
length = int(return_length.item())
|
||||
z_p = z_p[:, :, head: head + length]
|
||||
x_mask = x_mask[:, :, head: head + length]
|
||||
z_p = z_p[:, :, head : head + length]
|
||||
x_mask = x_mask[:, :, head : head + length]
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, g=g)
|
||||
return o, x_mask, (z, z_p, m_p, logs_p)
|
||||
|
|
@ -1258,8 +1258,8 @@ class SynthesizerTrnMs768NSFsid_nono(nn.Module):
|
|||
assert isinstance(return_length, torch.Tensor)
|
||||
head = int(skip_head.item())
|
||||
length = int(return_length.item())
|
||||
z_p = z_p[:, :, head: head + length]
|
||||
x_mask = x_mask[:, :, head: head + length]
|
||||
z_p = z_p[:, :, head : head + length]
|
||||
x_mask = x_mask[:, :, head : head + length]
|
||||
z = self.flow(z_p, x_mask, g=g, reverse=True)
|
||||
o = self.dec(z * x_mask, g=g)
|
||||
return o, x_mask, (z, z_p, m_p, logs_p)
|
||||
|
|
|
|||
|
|
@ -38,6 +38,7 @@ def spectral_de_normalize_torch(magnitudes):
|
|||
mel_basis = {}
|
||||
hann_window = {}
|
||||
|
||||
|
||||
def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
|
||||
"""Convert waveform into Linear-frequency Linear-amplitude spectrogram.
|
||||
|
||||
|
|
@ -51,7 +52,7 @@ def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False)
|
|||
Returns:
|
||||
:: (B, Freq, Frame) - Linear-frequency Linear-amplitude spectrogram
|
||||
"""
|
||||
|
||||
|
||||
# Window - Cache if needed
|
||||
global hann_window
|
||||
dtype_device = str(y.dtype) + "_" + str(y.device)
|
||||
|
|
@ -60,7 +61,7 @@ def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False)
|
|||
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(
|
||||
dtype=y.dtype, device=y.device
|
||||
)
|
||||
|
||||
|
||||
# Padding
|
||||
y = torch.nn.functional.pad(
|
||||
y.unsqueeze(1),
|
||||
|
|
@ -68,7 +69,7 @@ def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False)
|
|||
mode="reflect",
|
||||
)
|
||||
y = y.squeeze(1)
|
||||
|
||||
|
||||
# Complex Spectrogram :: (B, T) -> (B, Freq, Frame, RealComplex=2)
|
||||
spec = torch.stft(
|
||||
y,
|
||||
|
|
@ -82,11 +83,12 @@ def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False)
|
|||
onesided=True,
|
||||
return_complex=True,
|
||||
)
|
||||
|
||||
|
||||
# Linear-frequency Linear-amplitude spectrogram :: (B, Freq, Frame, RealComplex=2) -> (B, Freq, Frame)
|
||||
spec = torch.sqrt(spec.real.pow(2) + spec.imag.pow(2) + 1e-6)
|
||||
return spec
|
||||
|
||||
|
||||
def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
|
||||
# MelBasis - Cache if needed
|
||||
global mel_basis
|
||||
|
|
|
|||
|
|
@ -143,7 +143,7 @@ if __name__ == "__main__":
|
|||
# exp_dir=r"E:\codes\py39\dataset\mi-test"
|
||||
# n_p=16
|
||||
# f = open("%s/log_extract_f0.log"%exp_dir, "w")
|
||||
printt(sys.argv)
|
||||
printt(" ".join(sys.argv))
|
||||
featureInput = FeatureInput()
|
||||
paths = []
|
||||
inp_root = "%s/1_16k_wavs" % (exp_dir)
|
||||
|
|
|
|||
|
|
@ -106,7 +106,7 @@ if __name__ == "__main__":
|
|||
# exp_dir=r"E:\codes\py39\dataset\mi-test"
|
||||
# n_p=16
|
||||
# f = open("%s/log_extract_f0.log"%exp_dir, "w")
|
||||
printt(sys.argv)
|
||||
printt(" ".join(sys.argv))
|
||||
featureInput = FeatureInput()
|
||||
paths = []
|
||||
inp_root = "%s/1_16k_wavs" % (exp_dir)
|
||||
|
|
|
|||
|
|
@ -104,7 +104,7 @@ if __name__ == "__main__":
|
|||
# exp_dir=r"E:\codes\py39\dataset\mi-test"
|
||||
# n_p=16
|
||||
# f = open("%s/log_extract_f0.log"%exp_dir, "w")
|
||||
printt(sys.argv)
|
||||
printt(" ".join(sys.argv))
|
||||
featureInput = FeatureInput()
|
||||
paths = []
|
||||
inp_root = "%s/1_16k_wavs" % (exp_dir)
|
||||
|
|
|
|||
|
|
@ -8,14 +8,16 @@ os.environ["PYTORCH_MPS_HIGH_WATERMARK_RATIO"] = "0.0"
|
|||
device = sys.argv[1]
|
||||
n_part = int(sys.argv[2])
|
||||
i_part = int(sys.argv[3])
|
||||
if len(sys.argv) == 6:
|
||||
if len(sys.argv) == 7:
|
||||
exp_dir = sys.argv[4]
|
||||
version = sys.argv[5]
|
||||
is_half = bool(sys.argv[6])
|
||||
else:
|
||||
i_gpu = sys.argv[4]
|
||||
exp_dir = sys.argv[5]
|
||||
os.environ["CUDA_VISIBLE_DEVICES"] = str(i_gpu)
|
||||
version = sys.argv[6]
|
||||
is_half = bool(sys.argv[7])
|
||||
import fairseq
|
||||
import numpy as np
|
||||
import soundfile as sf
|
||||
|
|
@ -49,10 +51,10 @@ def printt(strr):
|
|||
f.flush()
|
||||
|
||||
|
||||
printt(sys.argv)
|
||||
printt(" ".join(sys.argv))
|
||||
model_path = "assets/hubert/hubert_base.pt"
|
||||
|
||||
printt(exp_dir)
|
||||
printt("exp_dir: " + exp_dir)
|
||||
wavPath = "%s/1_16k_wavs" % exp_dir
|
||||
outPath = (
|
||||
"%s/3_feature256" % exp_dir if version == "v1" else "%s/3_feature768" % exp_dir
|
||||
|
|
@ -91,8 +93,9 @@ models, saved_cfg, task = fairseq.checkpoint_utils.load_model_ensemble_and_task(
|
|||
model = models[0]
|
||||
model = model.to(device)
|
||||
printt("move model to %s" % device)
|
||||
if device not in ["mps", "cpu"]:
|
||||
model = model.half()
|
||||
if is_half:
|
||||
if device not in ["mps", "cpu"]:
|
||||
model = model.half()
|
||||
model.eval()
|
||||
|
||||
todo = sorted(list(os.listdir(wavPath)))[i_part::n_part]
|
||||
|
|
@ -114,7 +117,7 @@ else:
|
|||
padding_mask = torch.BoolTensor(feats.shape).fill_(False)
|
||||
inputs = {
|
||||
"source": feats.half().to(device)
|
||||
if device not in ["mps", "cpu"]
|
||||
if is_half and device not in ["mps", "cpu"]
|
||||
else feats.to(device),
|
||||
"padding_mask": padding_mask.to(device),
|
||||
"output_layer": 9 if version == "v1" else 12, # layer 9
|
||||
|
|
|
|||
|
|
@ -6,14 +6,13 @@ from scipy import signal
|
|||
|
||||
now_dir = os.getcwd()
|
||||
sys.path.append(now_dir)
|
||||
print(sys.argv)
|
||||
print(*sys.argv[1:])
|
||||
inp_root = sys.argv[1]
|
||||
sr = int(sys.argv[2])
|
||||
n_p = int(sys.argv[3])
|
||||
exp_dir = sys.argv[4]
|
||||
noparallel = sys.argv[5] == "True"
|
||||
per = float(sys.argv[6])
|
||||
import multiprocessing
|
||||
import os
|
||||
import traceback
|
||||
|
||||
|
|
@ -24,16 +23,13 @@ from scipy.io import wavfile
|
|||
from infer.lib.audio import load_audio
|
||||
from infer.lib.slicer2 import Slicer
|
||||
|
||||
mutex = multiprocessing.Lock()
|
||||
f = open("%s/preprocess.log" % exp_dir, "a+")
|
||||
|
||||
|
||||
def println(strr):
|
||||
mutex.acquire()
|
||||
print(strr)
|
||||
f.write("%s\n" % strr)
|
||||
f.flush()
|
||||
mutex.release()
|
||||
|
||||
|
||||
class PreProcess:
|
||||
|
|
@ -104,9 +100,9 @@ class PreProcess:
|
|||
idx1 += 1
|
||||
break
|
||||
self.norm_write(tmp_audio, idx0, idx1)
|
||||
println("%s->Suc." % path)
|
||||
println("%s\t-> Success" % path)
|
||||
except:
|
||||
println("%s->%s" % (path, traceback.format_exc()))
|
||||
println("%s\t-> %s" % (path, traceback.format_exc()))
|
||||
|
||||
def pipeline_mp(self, infos):
|
||||
for path, idx0 in infos:
|
||||
|
|
@ -138,7 +134,6 @@ class PreProcess:
|
|||
def preprocess_trainset(inp_root, sr, n_p, exp_dir, per):
|
||||
pp = PreProcess(sr, exp_dir, per)
|
||||
println("start preprocess")
|
||||
println(sys.argv)
|
||||
pp.pipeline_mp_inp_dir(inp_root, n_p)
|
||||
println("end preprocess")
|
||||
|
||||
|
|
|
|||
|
|
@ -104,10 +104,11 @@ def main():
|
|||
os.environ["MASTER_ADDR"] = "localhost"
|
||||
os.environ["MASTER_PORT"] = str(randint(20000, 55555))
|
||||
children = []
|
||||
logger = utils.get_logger(hps.model_dir)
|
||||
for i in range(n_gpus):
|
||||
subproc = mp.Process(
|
||||
target=run,
|
||||
args=(i, n_gpus, hps),
|
||||
args=(i, n_gpus, hps, logger),
|
||||
)
|
||||
children.append(subproc)
|
||||
subproc.start()
|
||||
|
|
@ -116,14 +117,10 @@ def main():
|
|||
children[i].join()
|
||||
|
||||
|
||||
def run(
|
||||
rank,
|
||||
n_gpus,
|
||||
hps,
|
||||
):
|
||||
def run(rank, n_gpus, hps, logger: logging.Logger):
|
||||
global global_step
|
||||
if rank == 0:
|
||||
logger = utils.get_logger(hps.model_dir)
|
||||
# logger = utils.get_logger(hps.model_dir)
|
||||
logger.info(hps)
|
||||
# utils.check_git_hash(hps.model_dir)
|
||||
writer = SummaryWriter(log_dir=hps.model_dir)
|
||||
|
|
|
|||
|
|
@ -307,14 +307,14 @@ class AudioPreDeEcho:
|
|||
sf.write(
|
||||
os.path.join(
|
||||
ins_root,
|
||||
"instrument_{}_{}.{}".format(name, self.data["agg"], format),
|
||||
"vocal_{}_{}.{}".format(name, self.data["agg"], format),
|
||||
),
|
||||
(np.array(wav_instrument) * 32768).astype("int16"),
|
||||
self.mp.param["sr"],
|
||||
) #
|
||||
else:
|
||||
path = os.path.join(
|
||||
ins_root, "instrument_{}_{}.wav".format(name, self.data["agg"])
|
||||
ins_root, "vocal_{}_{}.wav".format(name, self.data["agg"])
|
||||
)
|
||||
sf.write(
|
||||
path,
|
||||
|
|
@ -344,14 +344,14 @@ class AudioPreDeEcho:
|
|||
sf.write(
|
||||
os.path.join(
|
||||
vocal_root,
|
||||
"vocal_{}_{}.{}".format(name, self.data["agg"], format),
|
||||
"instrument_{}_{}.{}".format(name, self.data["agg"], format),
|
||||
),
|
||||
(np.array(wav_vocals) * 32768).astype("int16"),
|
||||
self.mp.param["sr"],
|
||||
)
|
||||
else:
|
||||
path = os.path.join(
|
||||
vocal_root, "vocal_{}_{}.wav".format(name, self.data["agg"])
|
||||
vocal_root, "instrument_{}_{}.wav".format(name, self.data["agg"])
|
||||
)
|
||||
sf.write(
|
||||
path,
|
||||
|
|
|
|||
File diff suppressed because it is too large
Load Diff
|
|
@ -1,64 +0,0 @@
|
|||
[tool.poetry]
|
||||
name = "rvc-beta"
|
||||
version = "0.1.0"
|
||||
description = ""
|
||||
authors = ["lj1995"]
|
||||
license = "MIT"
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = "^3.8"
|
||||
torch = "^2.0.0"
|
||||
torchaudio = "^2.0.1"
|
||||
Cython = "^0.29.34"
|
||||
gradio = "^3.34.0"
|
||||
future = "^0.18.3"
|
||||
pydub = "^0.25.1"
|
||||
soundfile = "^0.12.1"
|
||||
ffmpeg-python = "^0.2.0"
|
||||
tensorboardX = "^2.6"
|
||||
functorch = "^2.0.0"
|
||||
fairseq = "^0.12.2"
|
||||
faiss-cpu = "^1.7.2"
|
||||
Jinja2 = "^3.1.2"
|
||||
json5 = "^0.9.11"
|
||||
librosa = "0.9.1"
|
||||
llvmlite = "0.39.0"
|
||||
Markdown = "^3.4.3"
|
||||
matplotlib = "^3.7.1"
|
||||
matplotlib-inline = "^0.1.6"
|
||||
numba = "0.56.4"
|
||||
numpy = "1.23.5"
|
||||
scipy = "1.9.3"
|
||||
praat-parselmouth = "^0.4.3"
|
||||
Pillow = "9.3.0"
|
||||
pyworld = "^0.3.2"
|
||||
resampy = "^0.4.2"
|
||||
scikit-learn = "^1.2.2"
|
||||
starlette = "^0.27.0"
|
||||
tensorboard = "^2.12.1"
|
||||
tensorboard-data-server = "^0.7.0"
|
||||
tensorboard-plugin-wit = "^1.8.1"
|
||||
torchgen = "^0.0.1"
|
||||
tqdm = "^4.65.0"
|
||||
tornado = "^6.3"
|
||||
Werkzeug = "^2.2.3"
|
||||
uc-micro-py = "^1.0.1"
|
||||
sympy = "^1.11.1"
|
||||
tabulate = "^0.9.0"
|
||||
PyYAML = "^6.0"
|
||||
pyasn1 = "^0.4.8"
|
||||
pyasn1-modules = "^0.2.8"
|
||||
fsspec = "^2023.3.0"
|
||||
absl-py = "^1.4.0"
|
||||
audioread = "^3.0.0"
|
||||
uvicorn = "^0.21.1"
|
||||
colorama = "^0.4.6"
|
||||
torchcrepe = "0.0.20"
|
||||
python-dotenv = "^1.0.0"
|
||||
av = "^10.0.0"
|
||||
|
||||
[tool.poetry.dev-dependencies]
|
||||
|
||||
[build-system]
|
||||
requires = ["poetry-core>=1.0.0"]
|
||||
build-backend = "poetry.core.masonry.api"
|
||||
20
run.sh
20
run.sh
|
|
@ -1,27 +1,27 @@
|
|||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
|
||||
if [[ "$(uname)" == "Darwin" ]]; then
|
||||
if [ "$(uname)" = "Darwin" ]; then
|
||||
# macOS specific env:
|
||||
export PYTORCH_ENABLE_MPS_FALLBACK=1
|
||||
export PYTORCH_MPS_HIGH_WATERMARK_RATIO=0.0
|
||||
elif [[ "$(uname)" != "Linux" ]]; then
|
||||
elif [ "$(uname)" != "Linux" ]; then
|
||||
echo "Unsupported operating system."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -d ".venv" ]; then
|
||||
echo "Activate venv..."
|
||||
source .venv/bin/activate
|
||||
. .venv/bin/activate
|
||||
else
|
||||
echo "Create venv..."
|
||||
requirements_file="requirements.txt"
|
||||
|
||||
# Check if Python 3.8 is installed
|
||||
if ! command -v python3 &> /dev/null; then
|
||||
if ! command -v python3 >/dev/null 2>&1; then
|
||||
echo "Python 3 not found. Attempting to install 3.8..."
|
||||
if [[ "$(uname)" == "Darwin" ]] && command -v brew &> /dev/null; then
|
||||
if [ "$(uname)" = "Darwin" ] && command -v brew >/dev/null 2>&1; then
|
||||
brew install python@3.8
|
||||
elif [[ "$(uname)" == "Linux" ]] && command -v apt-get &> /dev/null; then
|
||||
elif [ "$(uname)" = "Linux" ] && command -v apt-get >/dev/null 2>&1; then
|
||||
sudo apt-get update
|
||||
sudo apt-get install python3.8
|
||||
else
|
||||
|
|
@ -31,13 +31,13 @@ else
|
|||
fi
|
||||
|
||||
python3 -m venv .venv
|
||||
source .venv/bin/activate
|
||||
. .venv/bin/activate
|
||||
|
||||
# Check if required packages are installed and install them if not
|
||||
if [ -f "${requirements_file}" ]; then
|
||||
installed_packages=$(python3 -m pip freeze)
|
||||
while IFS= read -r package; do
|
||||
[[ "${package}" =~ ^#.* ]] && continue
|
||||
expr "${package}" : "^#.*" > /dev/null && continue
|
||||
package_name=$(echo "${package}" | sed 's/[<>=!].*//')
|
||||
if ! echo "${installed_packages}" | grep -q "${package_name}"; then
|
||||
echo "${package_name} not found. Attempting to install..."
|
||||
|
|
@ -53,7 +53,7 @@ fi
|
|||
# Download models
|
||||
./tools/dlmodels.sh
|
||||
|
||||
if [[ $? -ne 0 ]]; then
|
||||
if [ $? -ne 0 ]; then
|
||||
exit 1
|
||||
fi
|
||||
|
||||
|
|
|
|||
|
|
@ -1,566 +1,81 @@
|
|||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
|
||||
echo working dir is $(pwd)
|
||||
echo downloading requirement aria2 check.
|
||||
printf "working dir is %s\n" "$PWD"
|
||||
echo "downloading requirement aria2 check."
|
||||
|
||||
if command -v aria2c &> /dev/null
|
||||
if command -v aria2c > /dev/null 2>&1
|
||||
then
|
||||
echo "aria2c command found"
|
||||
echo "aria2 command found"
|
||||
else
|
||||
echo failed. please install aria2
|
||||
sleep 5
|
||||
echo "failed. please install aria2"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
d32="f0D32k.pth"
|
||||
d40="f0D40k.pth"
|
||||
d48="f0D48k.pth"
|
||||
g32="f0G32k.pth"
|
||||
g40="f0G40k.pth"
|
||||
g48="f0G48k.pth"
|
||||
echo "dir check start."
|
||||
|
||||
d40v2="f0D40k.pth"
|
||||
g40v2="f0G40k.pth"
|
||||
check_dir() {
|
||||
[ -d "$1" ] && printf "dir %s checked\n" "$1" || \
|
||||
printf "failed. generating dir %s\n" "$1" && mkdir -p "$1"
|
||||
}
|
||||
|
||||
dld32="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D32k.pth"
|
||||
dld40="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D40k.pth"
|
||||
dld48="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D48k.pth"
|
||||
dlg32="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G32k.pth"
|
||||
dlg40="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G40k.pth"
|
||||
dlg48="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G48k.pth"
|
||||
check_dir "./assets/pretrained"
|
||||
check_dir "./assets/pretrained_v2"
|
||||
check_dir "./assets/uvr5_weights"
|
||||
check_dir "./assets/uvr5_weights/onnx_dereverb_By_FoxJoy"
|
||||
|
||||
dld40v2="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0D40k.pth"
|
||||
dlg40v2="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0G40k.pth"
|
||||
echo "dir check finished."
|
||||
|
||||
hp2_all="HP2_all_vocals.pth"
|
||||
hp3_all="HP3_all_vocals.pth"
|
||||
hp5_only="HP5_only_main_vocal.pth"
|
||||
VR_DeEchoAggressive="VR-DeEchoAggressive.pth"
|
||||
VR_DeEchoDeReverb="VR-DeEchoDeReverb.pth"
|
||||
VR_DeEchoNormal="VR-DeEchoNormal.pth"
|
||||
onnx_dereverb="vocals.onnx"
|
||||
rmvpe="rmvpe.pt"
|
||||
echo "required files check start."
|
||||
check_file_pretrained() {
|
||||
printf "checking %s\n" "$2"
|
||||
if [ -f "./assets/""$1""/""$2""" ]; then
|
||||
printf "%s in ./assets/%s checked.\n" "$2" "$1"
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c > /dev/null 2>&1; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/"$1"/"$2" -d ./assets/"$1" -o "$2"
|
||||
[ -f "./assets/""$1""/""$2""" ] && echo "download successful." || echo "please try again!" && exit 1
|
||||
else
|
||||
echo "aria2c command not found. Please install aria2c and try again."
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
}
|
||||
|
||||
dlhp2_all="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP2_all_vocals.pth"
|
||||
dlhp3_all="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP3_all_vocals.pth"
|
||||
dlhp5_only="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP5_only_main_vocal.pth"
|
||||
dlVR_DeEchoAggressive="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/VR-DeEchoAggressive.pth"
|
||||
dlVR_DeEchoDeReverb="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/VR-DeEchoDeReverb.pth"
|
||||
dlVR_DeEchoNormal="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/VR-DeEchoNormal.pth"
|
||||
dlonnx_dereverb="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/onnx_dereverb_By_FoxJoy/vocals.onnx"
|
||||
dlrmvpe="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt"
|
||||
check_file_special() {
|
||||
printf "checking %s\n" "$2"
|
||||
if [ -f "./assets/""$1""/""$2""" ]; then
|
||||
printf "%s in ./assets/%s checked.\n" "$2" "$1"
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c > /dev/null 2>&1; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/"$2" -d ./assets/"$1" -o "$2"
|
||||
[ -f "./assets/""$1""/""$2""" ] && echo "download successful." || echo "please try again!" && exit 1
|
||||
else
|
||||
echo "aria2c command not found. Please install aria2c and try again."
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
}
|
||||
|
||||
hb="hubert_base.pt"
|
||||
check_file_pretrained pretrained D32k.pth
|
||||
check_file_pretrained pretrained D40k.pth
|
||||
check_file_pretrained pretrained D48k.pth
|
||||
check_file_pretrained pretrained G32k.pth
|
||||
check_file_pretrained pretrained G40k.pth
|
||||
check_file_pretrained pretrained G48k.pth
|
||||
check_file_pretrained pretrained_v2 f0D40k.pth
|
||||
check_file_pretrained pretrained_v2 f0G40k.pth
|
||||
check_file_pretrained pretrained_v2 D40k.pth
|
||||
check_file_pretrained pretrained_v2 G40k.pth
|
||||
check_file_pretrained uvr5_weights HP2_all_vocals.pth
|
||||
check_file_pretrained uvr5_weights HP3_all_vocals.pth
|
||||
check_file_pretrained uvr5_weights HP5_only_main_vocal.pth
|
||||
check_file_pretrained uvr5_weights VR-DeEchoAggressive.pth
|
||||
check_file_pretrained uvr5_weights VR-DeEchoDeReverb.pth
|
||||
check_file_pretrained uvr5_weights VR-DeEchoNormal.pth
|
||||
check_file_pretrained uvr5_weights "onnx_dereverb_By_FoxJoy/vocals.onnx"
|
||||
check_file_special rmvpe rmvpe.pt
|
||||
check_file_special hubert hubert_base.pt
|
||||
|
||||
dlhb="https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt"
|
||||
|
||||
echo dir check start.
|
||||
|
||||
if [ -d "./assets/pretrained" ]; then
|
||||
echo dir ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. generating dir ./assets/pretrained.
|
||||
mkdir pretrained
|
||||
fi
|
||||
|
||||
if [ -d "./assets/pretrained_v2" ]; then
|
||||
echo dir ./assets/pretrained_v2 checked.
|
||||
else
|
||||
echo failed. generating dir ./assets/pretrained_v2.
|
||||
mkdir pretrained_v2
|
||||
fi
|
||||
|
||||
if [ -d "./assets/uvr5_weights" ]; then
|
||||
echo dir ./assets/uvr5_weights checked.
|
||||
else
|
||||
echo failed. generating dir ./assets/uvr5_weights.
|
||||
mkdir uvr5_weights
|
||||
fi
|
||||
|
||||
if [ -d "./assets/uvr5_weights/onnx_dereverb_By_FoxJoy" ]; then
|
||||
echo dir ./assets/uvr5_weights/onnx_dereverb_By_FoxJoy checked.
|
||||
else
|
||||
echo failed. generating dir ./assets/uvr5_weights/onnx_dereverb_By_FoxJoy.
|
||||
mkdir uvr5_weights/onnx_dereverb_By_FoxJoy
|
||||
fi
|
||||
|
||||
echo dir check finished.
|
||||
|
||||
echo required files check start.
|
||||
|
||||
echo checking D32k.pth
|
||||
if [ -f "./assets/pretrained/D32k.pth" ]; then
|
||||
echo D32k.pth in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D32k.pth -d ./assets/pretrained -o D32k.pth
|
||||
if [ -f "./assets/pretrained/D32k.pth" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking D40k.pth
|
||||
if [ -f "./assets/pretrained/D40k.pth" ]; then
|
||||
echo D40k.pth in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D40k.pth -d ./assets/pretrained -o D40k.pth
|
||||
if [ -f "./assets/pretrained/D40k.pth" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking D40k.pth
|
||||
if [ -f "./assets/pretrained_v2/D40k.pth" ]; then
|
||||
echo D40k.pth in ./assets/pretrained_v2 checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/D40k.pth -d ./assets/pretrained_v2 -o D40k.pth
|
||||
if [ -f "./assets/pretrained_v2/D40k.pth" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking D48k.pth
|
||||
if [ -f "./assets/pretrained/D48k.pth" ]; then
|
||||
echo D48k.pth in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D48k.pth -d ./assets/pretrained -o D48k.pth
|
||||
if [ -f "./assets/pretrained/D48k.pth" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking G32k.pth
|
||||
if [ -f "./assets/pretrained/G32k.pth" ]; then
|
||||
echo G32k.pth in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G32k.pth -d ./assets/pretrained -o G32k.pth
|
||||
if [ -f "./assets/pretrained/G32k.pth" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking G40k.pth
|
||||
if [ -f "./assets/pretrained/G40k.pth" ]; then
|
||||
echo G40k.pth in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G40k.pth -d ./assets/pretrained -o G40k.pth
|
||||
if [ -f "./assets/pretrained/G40k.pth" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking G40k.pth
|
||||
if [ -f "./assets/pretrained_v2/G40k.pth" ]; then
|
||||
echo G40k.pth in ./assets/pretrained_v2 checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/G40k.pth -d ./assets/pretrained_v2 -o G40k.pth
|
||||
if [ -f "./assets/pretrained_v2/G40k.pth" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking G48k.pth
|
||||
if [ -f "./assets/pretrained/G48k.pth" ]; then
|
||||
echo G48k.pth in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G48k.pth -d ./assets/pretrained -o G48k.pth
|
||||
if [ -f "./assets/pretrained/G48k.pth" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $d32
|
||||
if [ -f "./assets/pretrained/$d32" ]; then
|
||||
echo $d32 in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dld32 -d ./assets/pretrained -o $d32
|
||||
if [ -f "./assets/pretrained/$d32" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $d40
|
||||
if [ -f "./assets/pretrained/$d40" ]; then
|
||||
echo $d40 in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dld40 -d ./assets/pretrained -o $d40
|
||||
if [ -f "./assets/pretrained/$d40" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $d40v2
|
||||
if [ -f "./assets/pretrained_v2/$d40v2" ]; then
|
||||
echo $d40v2 in ./assets/pretrained_v2 checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dld40v2 -d ./assets/pretrained_v2 -o $d40v2
|
||||
if [ -f "./assets/pretrained_v2/$d40v2" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $d48
|
||||
if [ -f "./assets/pretrained/$d48" ]; then
|
||||
echo $d48 in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dld48 -d ./assets/pretrained -o $d48
|
||||
if [ -f "./assets/pretrained/$d48" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $g32
|
||||
if [ -f "./assets/pretrained/$g32" ]; then
|
||||
echo $g32 in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlg32 -d ./assets/pretrained -o $g32
|
||||
if [ -f "./assets/pretrained/$g32" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $g40
|
||||
if [ -f "./assets/pretrained/$g40" ]; then
|
||||
echo $g40 in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlg40 -d ./assets/pretrained -o $g40
|
||||
if [ -f "./assets/pretrained/$g40" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $g40v2
|
||||
if [ -f "./assets/pretrained_v2/$g40v2" ]; then
|
||||
echo $g40v2 in ./assets/pretrained_v2 checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlg40v2 -d ./assets/pretrained_v2 -o $g40v2
|
||||
if [ -f "./assets/pretrained_v2/$g40v2" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $g48
|
||||
if [ -f "./assets/pretrained/$g48" ]; then
|
||||
echo $g48 in ./assets/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlg48 -d ./assets/pretrained -o $g48
|
||||
if [ -f "./assets/pretrained/$g48" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $hp2_all
|
||||
if [ -f "./assets/uvr5_weights/$hp2_all" ]; then
|
||||
echo $hp2_all in ./assets/uvr5_weights checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlhp2_all -d ./assets/uvr5_weights -o $hp2_all
|
||||
if [ -f "./assets/uvr5_weights/$hp2_all" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $hp3_all
|
||||
if [ -f "./assets/uvr5_weights/$hp3_all" ]; then
|
||||
echo $hp3_all in ./assets/uvr5_weights checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlhp3_all -d ./assets/uvr5_weights -o $hp3_all
|
||||
if [ -f "./assets/uvr5_weights/$hp3_all" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $hp5_only
|
||||
if [ -f "./assets/uvr5_weights/$hp5_only" ]; then
|
||||
echo $hp5_only in ./assets/uvr5_weights checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlhp5_only -d ./assets/uvr5_weights -o $hp5_only
|
||||
if [ -f "./assets/uvr5_weights/$hp5_only" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $VR_DeEchoAggressive
|
||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoAggressive" ]; then
|
||||
echo $VR_DeEchoAggressive in ./assets/uvr5_weights checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlVR_DeEchoAggressive -d ./assets/uvr5_weights -o $VR_DeEchoAggressive
|
||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoAggressive" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $VR_DeEchoDeReverb
|
||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoDeReverb" ]; then
|
||||
echo $VR_DeEchoDeReverb in ./assets/uvr5_weights checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlVR_DeEchoDeReverb -d ./assets/uvr5_weights -o $VR_DeEchoDeReverb
|
||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoDeReverb" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $VR_DeEchoNormal
|
||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoNormal" ]; then
|
||||
echo $VR_DeEchoNormal in ./assets/uvr5_weights checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlVR_DeEchoNormal -d ./assets/uvr5_weights -o $VR_DeEchoNormal
|
||||
if [ -f "./assets/uvr5_weights/$VR_DeEchoNormal" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $onnx_dereverb
|
||||
if [ -f "./assets/uvr5_weights/onnx_dereverb_By_FoxJoy/$onnx_dereverb" ]; then
|
||||
echo $onnx_dereverb in ./assets/uvr5_weights/onnx_dereverb_By_FoxJoy checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlonnx_dereverb -d ./assets/uvr5_weights/onnx_dereverb_By_FoxJoy -o $onnx_dereverb
|
||||
if [ -f "./assets/uvr5_weights/onnx_dereverb_By_FoxJoy/$onnx_dereverb" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $rmvpe
|
||||
if [ -f "./assets/rmvpe/$rmvpe" ]; then
|
||||
echo $rmvpe in ./assets/rmvpe checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlrmvpe -d ./assets/rmvpe -o $rmvpe
|
||||
if [ -f "./assets/rmvpe/$rmvpe" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo checking $hb
|
||||
if [ -f "./assets/hubert/$hb" ]; then
|
||||
echo $hb in ./assets/hubert/pretrained checked.
|
||||
else
|
||||
echo failed. starting download from huggingface.
|
||||
if command -v aria2c &> /dev/null; then
|
||||
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M $dlhb -d ./assets/hubert/ -o $hb
|
||||
if [ -f "./assets/hubert/$hb" ]; then
|
||||
echo download successful.
|
||||
else
|
||||
echo please try again!
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo aria2c command not found. Please install aria2c and try again.
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
echo required files check finished.
|
||||
echo "required files check finished."
|
||||
|
|
|
|||
|
|
@ -46,22 +46,23 @@ def printt(strr, *args):
|
|||
# config.is_half=False########强制cpu测试
|
||||
class RVC:
|
||||
def __init__(
|
||||
self,
|
||||
key,
|
||||
pth_path,
|
||||
index_path,
|
||||
index_rate,
|
||||
n_cpu,
|
||||
inp_q,
|
||||
opt_q,
|
||||
config: Config,
|
||||
last_rvc=None,
|
||||
self,
|
||||
key,
|
||||
pth_path,
|
||||
index_path,
|
||||
index_rate,
|
||||
n_cpu,
|
||||
inp_q,
|
||||
opt_q,
|
||||
config: Config,
|
||||
last_rvc=None,
|
||||
) -> None:
|
||||
"""
|
||||
初始化
|
||||
"""
|
||||
try:
|
||||
if config.dml == True:
|
||||
|
||||
def forward_dml(ctx, x, scale):
|
||||
ctx.scale = scale
|
||||
res = x.clone().detach()
|
||||
|
|
@ -90,9 +91,13 @@ class RVC:
|
|||
self.pth_path: str = pth_path
|
||||
self.index_path = index_path
|
||||
self.index_rate = index_rate
|
||||
self.cache_pitch: np.ndarray = np.zeros(1024, dtype="int32")
|
||||
self.cache_pitchf = np.zeros(1024, dtype="float32")
|
||||
|
||||
self.cache_pitch: torch.Tensor = torch.zeros(
|
||||
1024, device=self.device, dtype=torch.long
|
||||
)
|
||||
self.cache_pitchf = torch.zeros(
|
||||
1024, device=self.device, dtype=torch.float32
|
||||
)
|
||||
|
||||
if last_rvc is None:
|
||||
models, _, _ = fairseq.checkpoint_utils.load_model_ensemble_and_task(
|
||||
["assets/hubert/hubert_base.pt"],
|
||||
|
|
@ -198,15 +203,17 @@ class RVC:
|
|||
self.index_rate = new_index_rate
|
||||
|
||||
def get_f0_post(self, f0):
|
||||
f0bak = f0.copy()
|
||||
f0_mel = 1127 * np.log(1 + f0 / 700)
|
||||
if not torch.is_tensor(f0):
|
||||
f0 = torch.from_numpy(f0)
|
||||
f0 = f0.float().to(self.device).squeeze()
|
||||
f0_mel = 1127 * torch.log(1 + f0 / 700)
|
||||
f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - self.f0_mel_min) * 254 / (
|
||||
self.f0_mel_max - self.f0_mel_min
|
||||
self.f0_mel_max - self.f0_mel_min
|
||||
) + 1
|
||||
f0_mel[f0_mel <= 1] = 1
|
||||
f0_mel[f0_mel > 255] = 255
|
||||
f0_coarse = np.rint(f0_mel).astype(np.int32)
|
||||
return f0_coarse, f0bak
|
||||
f0_coarse = torch.round(f0_mel).long()
|
||||
return f0_coarse, f0
|
||||
|
||||
def get_f0(self, x, f0_up_key, n_cpu, method="harvest"):
|
||||
n_cpu = int(n_cpu)
|
||||
|
|
@ -258,7 +265,7 @@ class RVC:
|
|||
self.inp_q.put((idx, x[:tail], res_f0, n_cpu, ts))
|
||||
else:
|
||||
self.inp_q.put(
|
||||
(idx, x[part_length * idx - 320: tail], res_f0, n_cpu, ts)
|
||||
(idx, x[part_length * idx - 320 : tail], res_f0, n_cpu, ts)
|
||||
)
|
||||
while 1:
|
||||
res_ts = self.opt_q.get()
|
||||
|
|
@ -273,7 +280,7 @@ class RVC:
|
|||
else:
|
||||
f0 = f0[2:]
|
||||
f0bak[
|
||||
part_length * idx // 160: part_length * idx // 160 + f0.shape[0]
|
||||
part_length * idx // 160 : part_length * idx // 160 + f0.shape[0]
|
||||
] = f0
|
||||
f0bak = signal.medfilt(f0bak, 3)
|
||||
f0bak *= pow(2, f0_up_key / 12)
|
||||
|
|
@ -298,7 +305,6 @@ class RVC:
|
|||
pd = torchcrepe.filter.median(pd, 3)
|
||||
f0 = torchcrepe.filter.mean(f0, 3)
|
||||
f0[pd < 0.1] = 0
|
||||
f0 = f0[0].cpu().numpy()
|
||||
f0 *= pow(2, f0_up_key / 12)
|
||||
return self.get_f0_post(f0)
|
||||
|
||||
|
|
@ -320,6 +326,7 @@ class RVC:
|
|||
def get_f0_fcpe(self, x, f0_up_key):
|
||||
if hasattr(self, "model_fcpe") == False:
|
||||
from torchfcpe import spawn_bundled_infer_model
|
||||
|
||||
printt("Loading fcpe model")
|
||||
if "privateuseone" in str(self.device):
|
||||
self.device_fcpe = "cpu"
|
||||
|
|
@ -329,20 +336,19 @@ class RVC:
|
|||
f0 = self.model_fcpe.infer(
|
||||
x.to(self.device_fcpe).unsqueeze(0).float(),
|
||||
sr=16000,
|
||||
decoder_mode='local_argmax',
|
||||
decoder_mode="local_argmax",
|
||||
threshold=0.006,
|
||||
)
|
||||
f0 *= pow(2, f0_up_key / 12)
|
||||
f0 = f0.squeeze().cpu().numpy()
|
||||
return self.get_f0_post(f0)
|
||||
|
||||
def infer(
|
||||
self,
|
||||
input_wav: torch.Tensor,
|
||||
block_frame_16k,
|
||||
skip_head,
|
||||
return_length,
|
||||
f0method,
|
||||
self,
|
||||
input_wav: torch.Tensor,
|
||||
block_frame_16k,
|
||||
skip_head,
|
||||
return_length,
|
||||
f0method,
|
||||
) -> np.ndarray:
|
||||
t1 = ttime()
|
||||
with torch.no_grad():
|
||||
|
|
@ -364,16 +370,16 @@ class RVC:
|
|||
t2 = ttime()
|
||||
try:
|
||||
if hasattr(self, "index") and self.index_rate != 0:
|
||||
npy = feats[0][skip_head // 2:].cpu().numpy().astype("float32")
|
||||
npy = feats[0][skip_head // 2 :].cpu().numpy().astype("float32")
|
||||
score, ix = self.index.search(npy, k=8)
|
||||
weight = np.square(1 / score)
|
||||
weight /= weight.sum(axis=1, keepdims=True)
|
||||
npy = np.sum(self.big_npy[ix] * np.expand_dims(weight, axis=2), axis=1)
|
||||
if self.config.is_half:
|
||||
npy = npy.astype("float16")
|
||||
feats[0][skip_head // 2:] = (
|
||||
torch.from_numpy(npy).unsqueeze(0).to(self.device) * self.index_rate
|
||||
+ (1 - self.index_rate) * feats[0][skip_head // 2:]
|
||||
feats[0][skip_head // 2 :] = (
|
||||
torch.from_numpy(npy).unsqueeze(0).to(self.device) * self.index_rate
|
||||
+ (1 - self.index_rate) * feats[0][skip_head // 2 :]
|
||||
)
|
||||
else:
|
||||
printt("Index search FAILED or disabled")
|
||||
|
|
@ -381,24 +387,22 @@ class RVC:
|
|||
traceback.print_exc()
|
||||
printt("Index search FAILED")
|
||||
t3 = ttime()
|
||||
p_len = input_wav.shape[0] // 160
|
||||
if self.if_f0 == 1:
|
||||
f0_extractor_frame = block_frame_16k + 800
|
||||
if f0method == "rmvpe":
|
||||
f0_extractor_frame = (
|
||||
5120 * ((f0_extractor_frame - 1) // 5120 + 1) - 160
|
||||
)
|
||||
pitch, pitchf = self.get_f0(input_wav[-f0_extractor_frame: ], self.f0_up_key, self.n_cpu, f0method)
|
||||
start_frame = block_frame_16k // 160
|
||||
end_frame = len(self.cache_pitch) - (pitch.shape[0] - 4) + start_frame
|
||||
self.cache_pitch[:] = np.append(self.cache_pitch[start_frame: end_frame], pitch[3:-1])
|
||||
self.cache_pitchf[:] = np.append(
|
||||
self.cache_pitchf[start_frame: end_frame], pitchf[3:-1]
|
||||
f0_extractor_frame = 5120 * ((f0_extractor_frame - 1) // 5120 + 1) - 160
|
||||
pitch, pitchf = self.get_f0(
|
||||
input_wav[-f0_extractor_frame:], self.f0_up_key, self.n_cpu, f0method
|
||||
)
|
||||
shift = block_frame_16k // 160
|
||||
self.cache_pitch[:-shift] = self.cache_pitch[shift:].clone()
|
||||
self.cache_pitchf[:-shift] = self.cache_pitchf[shift:].clone()
|
||||
self.cache_pitch[4 - pitch.shape[0] :] = pitch[3:-1]
|
||||
self.cache_pitchf[4 - pitch.shape[0] :] = pitchf[3:-1]
|
||||
cache_pitch = self.cache_pitch[None, -p_len:]
|
||||
cache_pitchf = self.cache_pitchf[None, -p_len:]
|
||||
t4 = ttime()
|
||||
p_len = input_wav.shape[0] // 160
|
||||
if self.if_f0 == 1:
|
||||
cache_pitch = torch.LongTensor(self.cache_pitch[-p_len: ]).to(self.device).unsqueeze(0)
|
||||
cache_pitchf = torch.FloatTensor(self.cache_pitchf[-p_len: ]).to(self.device).unsqueeze(0)
|
||||
feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1)
|
||||
feats = feats[:, :p_len, :]
|
||||
p_len = torch.LongTensor([p_len]).to(self.device)
|
||||
|
|
|
|||
Loading…
Reference in New Issue