5.7 KiB
Stable Diffusion web UI
A browser interface based on Gradio library for Stable Diffusion.
Original script with Gradio UI was written by a kind anonymopus user. This is a modification.

Installing and running
Stable Diffusion
This script assumes that you already have main Stable Diffusion sutff installed, assumed to be in directory /sd.
If you don't have it installed, follow the guide:
This repository's webgui.py is a replacement for kdiff.py from the guide.
Particularly, following files must exist:
/sd/configs/stable-diffusion/v1-inference.yaml/sd/models/ldm/stable-diffusion-v1/model.ckpt/sd/ldm/util.py/sd/k_diffusion/__init__.py
GFPGAN
If you want to use GFPGAN to improve generated faces, you need to install it separately.
Follow instructions from https://github.com/TencentARC/GFPGAN, but when cloning it, do so into Stable Diffusion main directory, /sd.
After that download GFPGANv1.3.pth and put it
into the /sd/GFPGAN/experiments/pretrained_models directory. If you're getting troubles with GFPGAN support, follow instructions
from the GFPGAN's repository until inference_gfpgan.py script works.
The following files must exist:
/sd/GFPGAN/inference_gfpgan.py/sd/GFPGAN/experiments/pretrained_models/GFPGANv1.3.pth
If the GFPGAN directory does not exist, you will not get the option to use GFPGAN in the UI. If it does exist, you will either be able to use it, or there will be a message in console with an error related to GFPGAN.
Web UI
Run the script as:
python webui.py
When running the script, you must be in the main Stable Diffusion directory, /sd. If you cloned this repository into a subdirectory
of /sd, say, the stable-diffusion-webui directory, you will run it as:
python stable-diffusion-webui/webui.py
When launching, you may get a very long warning message related to some weights not being used. You may freely ignore it. After a while, you will get a message like this:
Running on local URL: http://127.0.0.1:7860/
Open the URL in browser, and you are good to go.
Features
The script creates a web UI for Stable Diffusion's txt2img and img2img scripts. Following are features added that are not in original script.
GFPGAN
Lets you improve faces in pictures using the GFPGAN model. There is a checkbox in every tab to use GFPGAN at 100%, and also a separate tab that just allows you to use GFPGAN on any picture, with a slider that controls how strongthe effect is.

Sampling method selection
Pick out of three sampling methods for txt2img: DDIM, PLMS, k-diffusion:

Prompt matrix
Separate multiple prompts using the | character, and the system will produce an image for every combination of them.
For example, if you use a busy city street in a modern city|illustration|cinematic lighting prompt, there are four combinations possible (first part of prompt is always kept):
a busy city street in a modern citya busy city street in a modern city, illustrationa busy city street in a modern city, cinematic lightinga busy city street in a modern city, illustration, cinematic lighting
Four images will be produced, in this order, all with same seed and each with corresponding prompt:
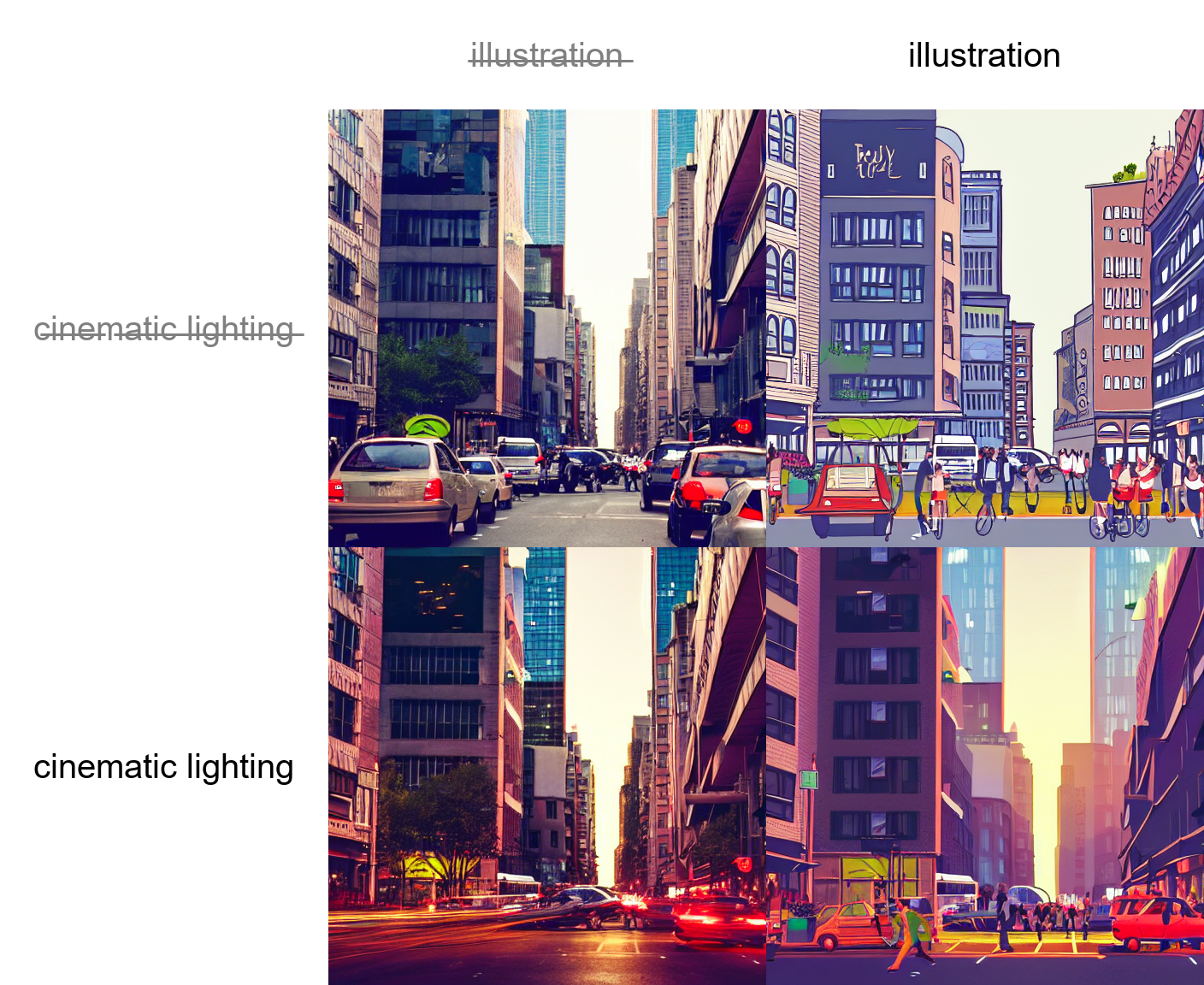
Another example, this time with 5 prompts and 16 variations:

If you use this feature, batch count will be ignored, because the number of pictures to produce depends on your prompts, but batch size will still work (generating multiple pictures at the same time for a small speed boost).
Flagging
Click the Flag button under the output section, and generated images will be saved to log/images directory, and generation parameters
will be appended to a csv file log/log.csv in the /sd directory.
Copy-paste generation parameters
A text output provides generation parameters in an easy to copy-paste form for easy sharing.
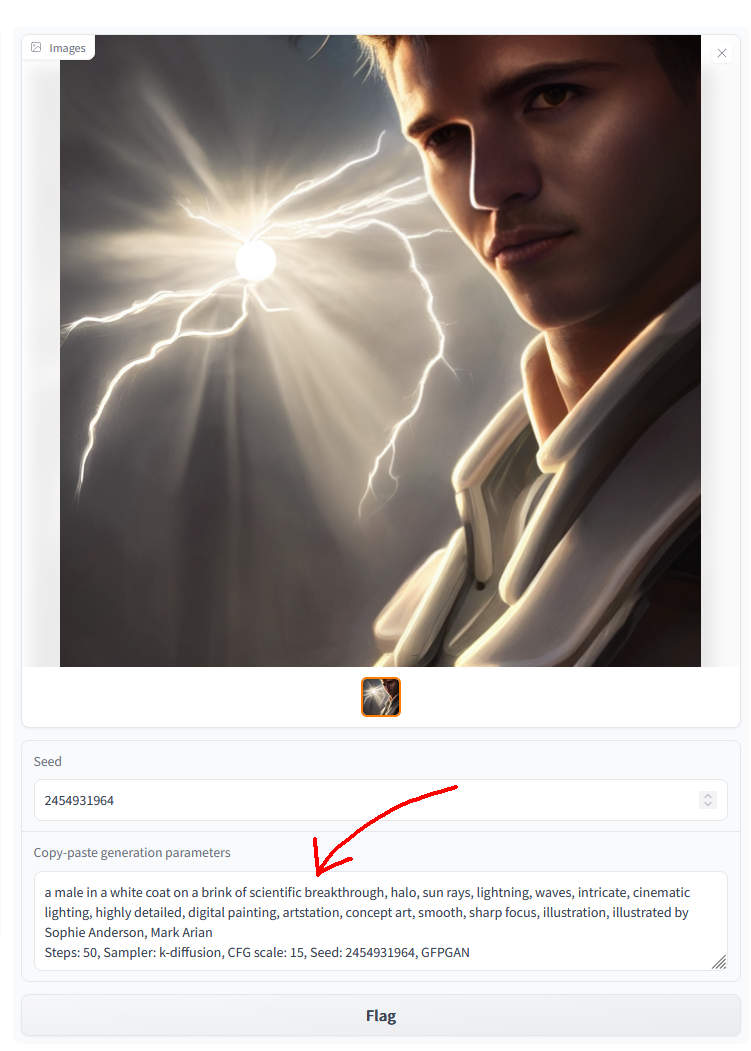
If you generate multiple pictures, the displayed seed will be the seed of the first one.
Correct seeds for batches
If you use a seed of 1000 to generate two batches of two images each, four generated images will have seeds: 1000, 1001, 1002, 1003.
Previous versions of the UI would produce 1000, x, 1001, x, where x is an iamge that can't be generated by any seed.
Resizing
There are three options for resizing input images in img2img mode:
- Just resize - simply resizes source image to target resolution, resulting in incorrect aspect ratio
- Crop and resize - resize source image preserving aspect ratio so that entirety of target resolution is occupied by it, and crop parts that stick out
- Resize and fill - resize source image preserving aspect ratio so that it entirely fits target resolution, and fill empty space by rows/columns from source image
Example:

Loading
Gradio's loading graphic has a very negative effect on the processing speed onthe neural network. My RTX 3090 makes images about 10% faster when the tab with gradio is not active. By defaul, the UI now hides loading progress animation and replaces it with static "Loading..." text. Use the --no-progressbar-hiding commandline option to revert this and show loading animations.
Prompt validation
Stable Diffusion has a limit for imput text length. If your prompt is too long, you will get a warning in the text output field, showing which parts of your text were truncated and consequently ignored by the model.